選挙が近づくと選挙関係者は公的機関が発表する選挙データを見ることが多くなります。具体的には選挙管理委員会が公開するデータから投票率の傾向、政党の地域ごとの得票率の確認です。この選挙管理委員会が公開するデータを基に各種分析を行うのですが、分析作業に入る前段階の作業に多くの手間がかかる形式で公開されている選挙管理委員会が多いのです。
今回は2303年8月6日に知事選が予定されている埼玉県選挙管理委員会が公開するデータが、使い勝手の良いものかどうかを観察したいと思います。
使い勝手の良いデータとはどのようなデータのことか?
使い勝手の良いデータというのは、選挙管理委員会職員の*業負担が軽減され、なおかつデータ利用を考えている有権者、政党、候補者等、市民誰もがメリットを享受*することができます。
それでは具体的に埼玉県選挙管理委員会のデータ形式について観察します。
埼玉県選挙管理員会が選挙結果データを公開するウェブサイトはこちら( https://www.pref.saitama.lg.jp/e1701/senkyo-data.html )になります。(2023年8月2日閲覧)
この中で知事選挙が掲載されている 埼玉県知事選挙結果のページはこちら( https://www.pref.saitama.lg.jp/e1701/chijisen-top.html )になります。
上記ページを閲覧すると、平成19年から令和元年までの知事選選挙結果データが存在することがわかります。ただ今後時間が経過するにつれてデータが蓄積されてきます。
そうなると和暦だけではなく西暦で選挙執行日を掲載した方が閲覧者は一目見ただけで、いつ選挙があったのかを理解しやすくなります。
この点については、総務省 統計表における機械判読可能なデータ 作成に関する表記方法には【□チェック項目1-11 e-Stat の時間軸コードの表記、西暦表記又は和暦に西暦の併記がされているか】とあるように西暦をタイトルに付けるとよりわかりやすくなるはずです。
(参考資料 総務省 2020年12月18日報道発表 統計表における機械判読可能なデータの表記方法の統一ルールの策定 )
たとえばこのように改善してみてはいかがでしょうか?
//////////////////////////////////////////////
埼玉県知事選挙(2019年_令和元年8月25日(日曜日)投票)
埼玉県知事選挙(2015年_平成27年8月9日(日曜日)投票)
埼玉県知事選挙(2011年_平成23年7月31日(日曜日)投票)
埼玉県知事選挙(2007年_平成19年8月26日(日曜日)投票)
//////////////////////////////////////////////
西暦表記が入ることで閲覧者が頭の中で和暦西暦を変換することなく時間関係を把握することができます。
次に前回知事選の令和元年8月25日執行ページを見てみます。

こちらをみるとエクセルファイルとPDFファイルが併存しています。データ操作がしやすいエクセル形式と印刷する際にレイアウトが保存されているPDF形式が併存しています。
これはデータ活用したい人と印刷物があれば事足りる人の両方の人に優しい設定になっています。
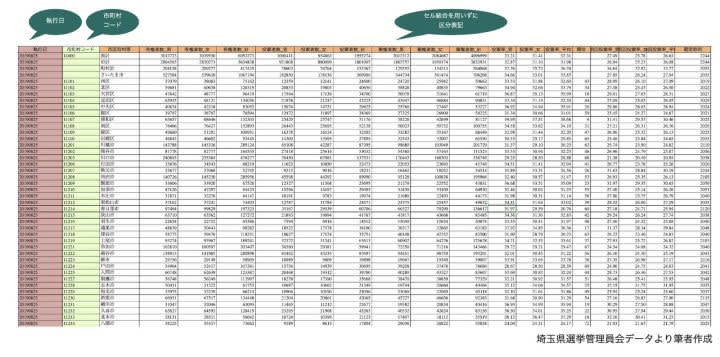
次に 確定ファイルである「確定(23時45分訂正)(エクセル:49KB)」を開くと下図のようになっています。

エクセルファイルでデータが公開されているのでデータ利用がしやすいのではないかと期待をしました。しかしながらファイルを開いてみるとデータ利活用しにくい表形式でした。
どの部分が利用しにくいのかについて総務省資料に基づいて3点ほど箇条書きにしてみます。
1、セル結合が用いられている(緑部分)
2、データ途中に執行日、結果、書類タイトルが記載されている(オレンジ部分)
3、市区町村名に自治体コードが振られていない
使いやすいデータにするための3つのコツ
まず1について、セル結合が用いられているとデータの並び替え等ができません。
データは投票率を高い順に並び替えたり、低い順に並び替えたりして情報を比較することで意味を持ちます。セル結合がなされているとデータの並び替えができないことが多くあります。したがって数値の並び替えをするにはセル結合を解除する必要があります。
最初から公開データにセル結合が利用されていなければ、セル結合を解除するという手間が省けます。
使い勝手の良いデータというのはどれだけ機械的にデータ処理ができるかです。
というのは機械的にデータ処理ができれば、たとえミスが発見された場合でもプログラムで一括処理することで修正可能になることが多いからです。
2については表計算シートの行にはそれぞれ有権者数、投票者数、棄権者数、投票率等が記載されています。しかし、シートの途中に埼玉県知事選挙 市町村別投票状況という文字列が入っています。赤の点線で囲った部分です。この部分ではセル結合も利用されています
このような状態があるとデータの並び替え等ができません。そのために赤の点線で囲った部分を削除する作業が必要となります。機械的に処理するために簡単なスクリプトを書けば済むこともありますが、最初からこの部分がないデータであればその作業は必要なくなります。
最後に3についてです。自治体コードが割り振られていないとデータを並び替えた際に、再び自治体順に並び替えることがしにくくなります。
どのようなことかというと、たとえば投票率が高い順に市区町村を並び替えたとします。
そうすると投票率が高い順から低い順に並び替えられますが、並び替え作業を何回もすると、市区町村の並びを最初の状態に戻すことが手間になります。そのようなことを考えると自治体コードを最初から割り振りしておけば自動的に自治体順に並び替えることができます。
また自治体コードを振る利点としては地理情報システム(GIS:Geographic Information System)と選挙データを連動しやすくなります。たとえば地域ごとの色分け図を作成するのが簡単にできるようになります。
埼玉県選挙管理委員会では市区町村ごとの投票率が平均以上かそうではないかを比較する塗り分け地図を公表しています。(参照サイトはこちら)
上記のような色分け地図も市区町村コードがきちんと振り付けられていれば一瞬で作成できます。地図作成時間を短縮することで、どの地域の投票率が低く、投票率向上のためにはどのような政策を取れば良いのか?等職員が思考する時間を多く取れるようになります。また事務的作業時間が短縮されるので職員負担も軽減されるものと思われます。
そのためにはきちんとした選挙結果データを作成することが選挙管理委員会に求められます。またこのようなきちんとした形式で公開されたデータはその地域に住む市民等もデータ活用が楽になります。
使いやすいデータの公開と蓄積をすべき理由は
データ駆動型社会等言われますが、その社会というのはこのような小さな積み重ねである、丁寧なデータの作り込みが必要となります。そしてその小さな積み重ねが大きな効率化を産み出します。
行政DX、RPA、EBPM(証拠に基づく政策立案)等、行政の効率化や証拠に基づいた行政について華々しい言葉が次々と世の中に流通しています。そのような単語で人々の関心を惹きつけることも大切だと思いますが、言葉だけではなく、個人情報、特に人種、信条、社会的身分、病歴、犯罪の経歴、身体/知的/精神障害等の「要保護情報*」を厳重保護し、
1:正確にデータを数え、
2:正確に記録し、
3:利活用しやすいデータが官公庁から公開され、
4:国民全体でデータ検証することができる状態を整えることが、
これからのより良い社会の形成につながるものと思います。
(筆者注 政府広報オンラインより 「要保護情報」についてhttps://www.gov-online.go.jp/useful/article/201703/1.html )
特に国、地域の代表者を決める選挙に関係するデータは、その後にしっかりと国の歩みを検証できるものとして残す必要があります。
選挙結果といえば、投票率、得票率、何票差で誰が当選をしたといった点に注目が集まりがちですが、利活用しやすいデータを公開、蓄積することも行政機関、各都道府県選挙管理委員会に課された役割です。
今回は埼玉県選挙管理委員会が公開するデータを総務省基準で作ってみるとどうなるか?について見てきました。
追記:総務省基準でデータ作成した投票率データの一例をあげます。
【★告知★】
選挙におけるビッグデータ分析の最先端を走るアメリカの最新事情を解説するネット選挙フォーラムが8月23日に開催されます!「アメリカ大統領選挙に見る ネット選挙とNIPPONの可能性」など9つのここでしか聞けないセッションを用意しています。
来場無料、オンライン同時開催ですので、今すぐお申込みください。
詳細・申込はコチラ>>https://netsenkyoforum.com/

