
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第32回目は、生成AI最新論文の概要5つを紹介します。
USB Type-CをMagSafe風にするマグネット式ケーブルは本当に使えるのか? 7製品を徹底チェックしてみた:#てくのじ何でも実験室
生成AI論文ピックアップ
“本当に”オープンな強力言語モデル「OLMo」、アレン人工知能研究所などが開発
言語モデル(LM)は、自然言語処理(NLP)の研究や商業製品に広く利用されています。商業的重要性が高まる中、最も強力なモデルは独自のインタフェースの背後に隠され、そのトレーニングデータやアーキテクチャの重要な詳細が非公開になっていました。これらの詳細を科学的に研究するためには、研究コミュニティが強力で真にオープンなLMにアクセスできることが不可欠です。
マイクロソフト共同創設者である故ポール・アレン氏によって設立された非営利研究機関「アレン人工知能研究所」(Allen Institute for AI、AI2)と米国の大学による研究チームは、“本当に”オープンな最先端の言語モデルフレームワーク「OLMo」(Open Language Model)を開発しました。
OLMoは、モデルの重みと推論コードのみを公開してきた先行研究の多くとは異なり、トレーニングとモデリングのコード、トレーニング済みモデルの重み(500以上の中間チェックポイントを含む)、トレーニングデータセット(Dolma)、データセット構築ツールキット(Dolmaのツールキット)、さまざまな評価コードなどが提供されています。
また、トレーニングログ、アブレーション、Weights & Biasesログ、指示チューニングとRLHFを用いたOLMoの適応版、そのトレーニングと評価コードなども将来的に公開される予定です。
Dolmaデータセット上で約2.46兆トークンまでトレーニングした「OLMo-7B」を他の公開されている言語モデルと比較しました。これにはLLaMA-7B、LLaMA2-7B、MPT-7B、Pythia-6.9B、Falcon-7B、RPJ-INCITE-7Bなどが含まれます。OLMo-7Bは、評価された9つの主要なタスクのうち2つで他のモデルを上回り、8つのタスクで上位3位以内にランクインしました。


OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
Paper | GitHub
推論効率の良い新たな視覚言語モデル「MoE-LLaVA」はLLaVA-1.5-7Bを上回る性能
大規模視覚言語モデル(LVLM)において、モデルの規模を拡大する場合、パラメータを大きくすると、計算時に各トークンで全てのパラメータが活性化されるため、トレーニングと推論のコストが大幅に増加します。
「MoE-LLaVA」という新しいLVLMフレームワークは、MoE(Mixture of Experts)をベースにしており、計算コストを維持しつつ、モデルのパラメータ数を大幅に拡張します。このフレームワークでは、複数の小さいニューラルネットワーク「Expert」を組み合わせて使用し、それぞれが特定のタイプのデータやタスクに特化しています。
MoE-LLaVA内のルーターは、入力データ(トークン)を適切なExpertに割り当てる役割を担っています。その結果、各トークンは最も適したExpertによって処理され、効率的なデータ処理が行われます。MoE-LLaVAはスパースな構造を持つため、アクティブなExpertは入力データを共同で処理し、非アクティブなExpertは使用されません。この選択的な活性化により、効率的な学習と高速な処理が可能となります。
MoE-LLaVAは2.2B(22億)のスパースに活性化されたパラメータを持ち、同様のパラメータ数を持つ他のモデルや、LLaVA-1.5-13Bモデルよりも高い性能を示しています。特に、「POPE object hallucination benchmark」という評価基準において、大きな差をつけています。さらに、MoE-LLaVAは「InternVL-Chat-19B」と同等の性能を達成しており、これはアクティブパラメーターが約8倍です。MoE-LLaVAを3.6B(36億)のスパースに活性化されたパラメータに拡大すると、LLaVA-1.5-7Bよりも様々な評価基準で性能向上が見られます。



MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, Li Yuan
Paper | GitHub | Demo
訓練データに含まれていない画像内オブジェクトもテキスト入力で検出可能な「YOLO-World」、テンセントが開発
物体検出における「YOLO」(You Only Look Once)は、効率的で実用的なツールとして確立されていますが、事前に定義され訓練されたオブジェクトカテゴリーに依存しているため、オープンなシナリオでの適用性に限界があります。
この限界に対処するため、「YOLO-World」という新しいアプローチが開発されました。YOLO-Worldは訓練データセットに含まれない新しい種類の画像内のオブジェクトも効果的に識別し、入力テキストに基づいてそれらをリアルタイムに分類する能力を持ちます。
この手法は、新しい「RepVL-PAN」(Re-parameterizable Vision-Language Path Aggregation Network)を採用し、テキストと画像の情報を統合して効率的な展開のために再パラメータ化することが可能です。また、検出、基準、画像-テキストデータを用いた事前トレーニングスキームを採用し、これによってオープン・ボキャブラリー検出において高い能力を持ちます。
YOLO-WorldはLVISデータセットにおいて、YOLO-Worldは速度(フレーム毎秒)とオープン・ボキャブラリー性能(平均精度)の両面で多くの最先端の方法を上回る性能を示しました。
さらに、ファインチューニングされたYOLO-Worldは、オブジェクト検出やオープン・ボキャブラリーインスタンスセグメンテーションなど、複数の下流タスクで顕著なパフォーマンスを達成しています。

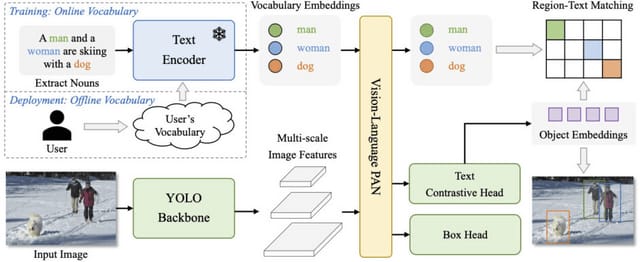
YOLO-World: Real-Time Open-Vocabulary Object Detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
Project | Paper | GitHub | Demo
0.2秒以内にスマホで高品質な画像を生成するモデル「MobileDiffusion」、Googleが開発
テキストから高品質な画像を生成するText-to-Image拡散モデルは画像編集やビデオ合成など多様な応用がありますが、大規模な計算資源を必要とし、モバイルデバイスへの適用は困難です。主な課題は、反復的なノイズ除去の必要性と複雑なネットワーク構造による高い計算コストです。
これまでの研究は、評価回数の削減に焦点を当てており、効率化のために数値ソルバーや蒸留技術を利用しています。しかし、モデルのアーキテクチャ効率性に関する研究は限られていました。
このギャップに対応し、研究者たちはパラメータが4億未満の軽量モデル「MobileDiffusion」を開発しました。このモデルは、アーキテクチャとサンプリング技術の両方において広範な最適化が施され、冗長性を減らし、計算効率を高め、パラメータ数を最小限に抑えつつ、画像生成の品質を維持しています。また、蒸留技術と拡散GAN微調整技術を使用し、それぞれ8ステップと1ステップの推論を可能にしています。
MobileDiffusionは、iPhone 15 Proで0.2秒以内に高品質な512×512画像を生成することに成功しました。これは、モバイルデバイス上でのText-to-Image生成におけるこれまでの最先端技術を大きく上回る結果です。




MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
Yang Zhao, Yanwu Xu, Zhisheng Xiao, Tingbo Hou
Paper
GPT-4Vを使用したスマホ自動操作システム「Mobile-Agent」、アリババなどが開発
Mobile-Agentは、視覚的知覚ツールを利用する自律型モバイルデバイスエージェントです。Mobile-Agentは、アプリのフロントエンドインタフェース内の視覚的およびテキスト要素を正確に識別し、認識された視覚コンテキストに基づいて、複雑な操作タスクを自動的に計画し、分解し、ステップバイステップでモバイルアプリを自動操作します。
XMLファイルやモバイルシステムのメタデータに依存する従来のソリューションとは異なり、Mobile-Agentは視覚中心のアプローチにより、多様なモバイル運用環境に対して強化された適応性を提供します。
このフレームワークは、最先端のマルチモーダル大規模言語モデル(MLLM)であるGPT-4V、およびテキストとアイコンの位置を特定するモジュールを含んでいます。GPT-4Vは正しい操作を提供しますが、操作の位置を特定する能力に欠けているため、外部ツールがサポートされます。
Mobile-AgentはOCRツールを使用して画面上のテキストの位置を特定し、アイコン検出ツールとCLIPを用いてアイコンの位置を特定します。Mobile-Agentは、ユーザーからの指示に基づいて各ステップを自己計画し、操作中に発生するエラーに対して自己反省を行い、必要に応じて操作を修正します。
Mobile-Agentの性能を評価するために「Mobile-Eval」というベンチマークが導入されました。これは10種類の一般的に使用されるモバイルアプリを含み、さまざまな難易度レベルの指示が含まれています。実験の結果、Mobile-Agentは高い指示完了率と操作精度を達成しました。複数のアプリを操作するなどの難しい指示でも、タスクを成功裏に完了することができました。



Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang
Paper | GitHub
YouTube広告を16倍速であっという間に終わらせるChrome拡張が公開、広告ブロック警告を回避

