1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第34回目は、生成AI最新論文の概要5つを紹介します。
テスラCybertruck、早くもサビ始める。複数のオーナーがステンレスの「ボディ表面に錆が発生」と報告
生成AI論文ピックアップ
1時間以上の長時間動画や100万トークンの長文を処理できるオープンソースモデル「LWM」、UCバークレーが開発
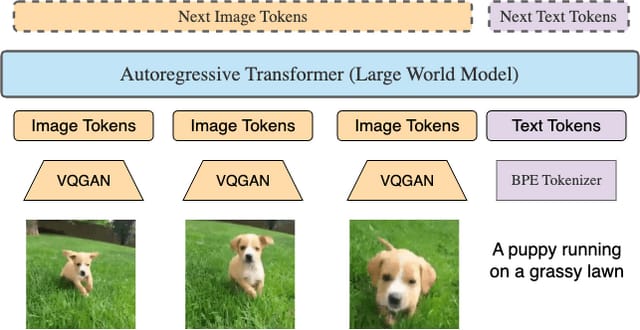
「Large World Model」(LWM)は、テキスト、画像、ビデオを理解し生成する能力を持つマルチモーダルモデルです。このモデルは、100万トークンの膨大な情報量を処理でき、テキストから画像やビデオを生成したり、画像や長時間のビデオに関する詳細な質問に回答することが可能です。
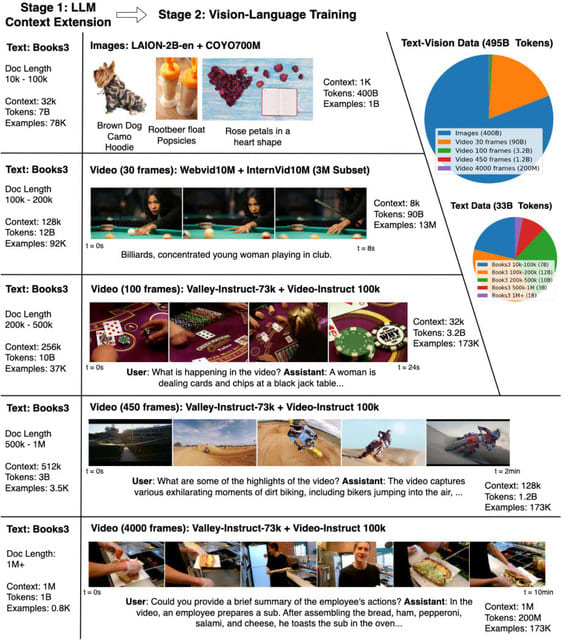
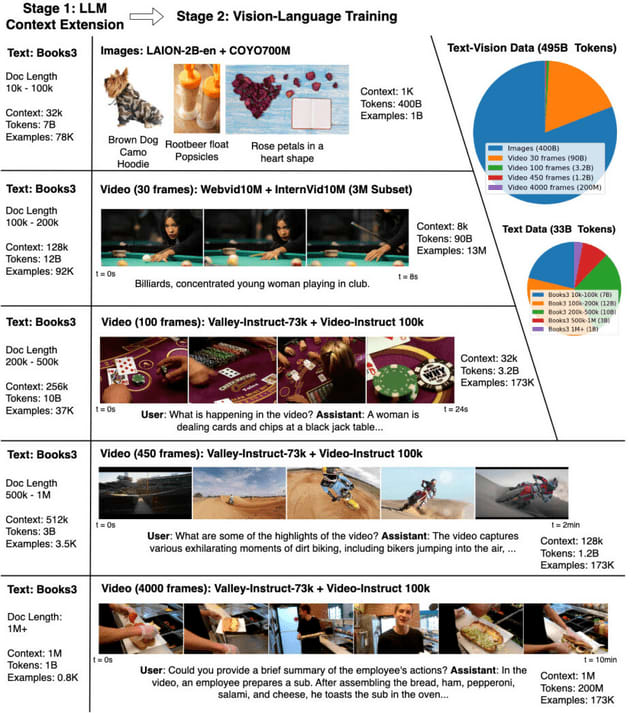
LWMの開発には、幅広いビデオと書籍から構成される大規模なデータセットが使用されています。学習プロセスでは、RingAttention技術を使用してコンテキストサイズを任意にスケールアップし、効率的に学習を促進します。具体的には、学習の初期段階でのコンテキストサイズを4000から始め、段階的に100万に増やしていきます。この段階的な拡大により、計算コストを管理しつつ、モデルがより広範なコンテキストを理解できるようになります。
また、マスク付きシーケンスパッキング技術を利用することで、異なる形式のデータを同時に扱うことができます。さらに、言語とビジョンのバランスを取るために、損失の重み付けを調整します。長い形式のチャットデータが不足している問題に対処するため、モデルによって生成されたQAデータセットを使用して、長いシーケンスの会話能力を学習します。
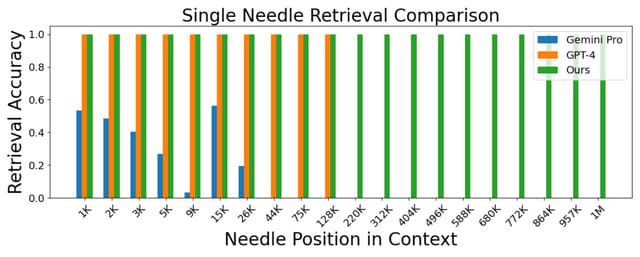
LWMは、1時間以上のYouTubeビデオから正確なQA応答を生成する能力を示しました。これは、Gemini Pro Vision、GPT-4V、および他のオープンソースモデルと比較して、質的に優れた結果を示します。LWMは、3万2000から12万8000のコンテキスト長でGemini ProやGPT-4に比肩し、100万トークンまで8倍長いコンテキスト長でも競争力のある性能を発揮しました。
研究チームは、RingAttentionやマスク付きシーケンスパッキングなどの技術を備えた高度に最適化された実装と、100万トークン以上の長文ドキュメント(LWM-Text, LWM-Text-Chat)およびビデオ(LWM, LWM-Chat)を処理できる7Bパラメータモデルをオープンソース化しました。



World Model on Million-Length Video And Language With RingAttention
Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel
Project | Paper | GitHub
Microsoft、テキスト指示でWindowsを自動操作できるAIエージェントシステム「UFO」を開発
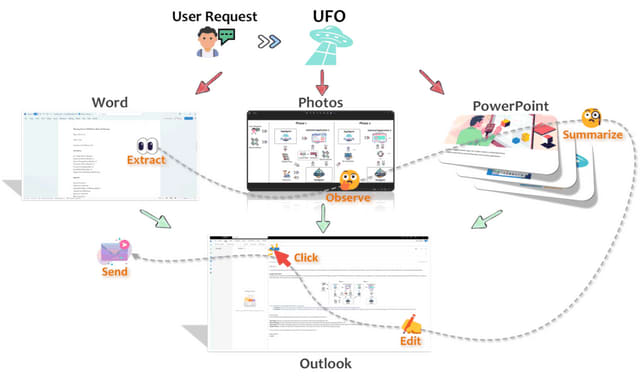
マルチモーダルな大規模言語モデルであるGPT-Visionを活用し、Windows上のアプリケーションと自然言語でやり取りするために設計されたUIに焦点を当てたエージェントシステム「UFO」(UI-Focused Agent)を提案しています。
スクリーンショットからGUIや制御情報を分析・抽出してアプリケーションを選択し、自然言語でのリクエストを満たすために人間のユーザーを模倣した行動を実行します。Windows上のアプリケーションには、Edge、Excel、Word、PowerPoint、Outlook、Visual Studio Codeなどが含まれ、これらを横断してテキスト指示に従った操作を行います。
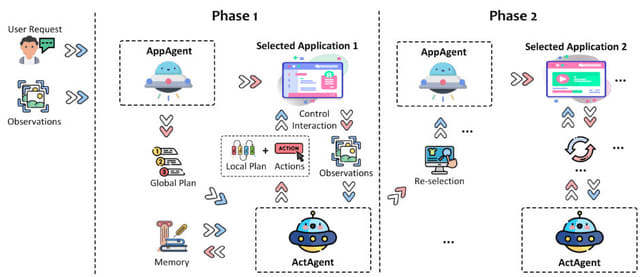
UFOは2段階のエージェントフレームワークとして動作し、アプリケーション選択エージェント(AppAgent)とアクション選択エージェント(ActAgent)の2つのコンポーネントを含みます。
AppAgentはユーザーリクエストを満たすためのアプリケーションを選択し、必要に応じて異なるアプリケーションに切り替えます。ActAgentは選択されたアプリケーションでアクションを繰り返し実行し、タスクが特定のアプリケーション内で成功裏に完了するまで操作を続けます。両エージェントは、GPT-Visionのマルチモーダルな能力を活用してアプリケーションUIを理解し、ユーザーのリクエストを満たします。
このシステムは完全な自動化を実現し、ユーザーの日常的なコンピューター作業を単純化し、長く複雑なプロセスをテキストコマンドだけで達成可能な簡単なタスクに変換します。また、UFOは複数のアプリケーション間でスムーズに切り替える機能を持ち、拡張性が高いため、特定のタスクやアプリケーションに合わせたカスタマイズが可能です。
UFOの有効性を評価するために、9つの広く使用されているアプリケーションにおいて50のタスクでテストを行い、その頑健性と適応性を実証しました。

UFO: A UI-Focused Agent for Windows OS Interaction
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
Paper | GitHub
ビデオ内を理解するために、動画内の一部を自ら隠して予測する学習方法「V-JEPA」をMetaが開発
Metaが開発したV-JEPA(Video Joint Embedding Predictive Architecture)は、ビデオから視覚表現を学習するための新しいアプローチです。V-JEPAは、アクション認識、モーション分類、オブジェクト認識など、時間的なビデオ解析の複数の側面において高い性能を発揮します。
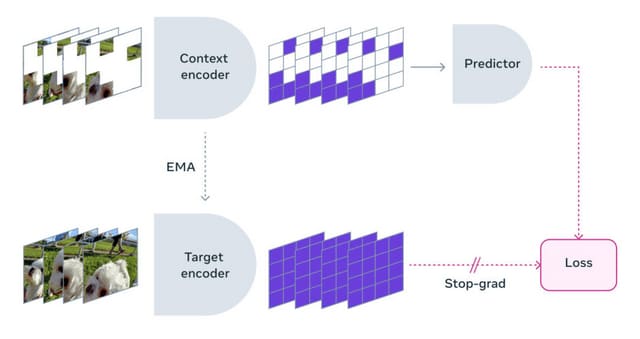
この方法では、動画内の一部をランダムかつ時間的に隠して、残された情報から隠された部分(マスク)の特徴を予測することにより、動画内の理解を深めます。マスクの予測を難しくするために、映像の一部を空間的にも時間的にもマスクするアプローチを採用しています。
この学習方法は、ピクセルレベルでの正確な再現ではなく、動画の特徴や内容を抽象的な特徴空間で予測することに焦点を当てています。これにより、モデルは動画内の重要な情報やパターンを効率的に学習し、不確実性や予測不可能な情報を無視することが可能になります。V-JEPAの訓練には、約200万本の公開ビデオデータセットから収集した動画が使用され、自己教師あり学習によりモデルを訓練しています。
V-JEPAは、事前学習された画像エンコーダー、テキスト、人間の注釈、ピクセルレベルの再構成などを使用せずに、ビデオの特徴を予測することにより、大量のラベル付けされていない動画データを活用して視覚的表現を学ぶ新しい方法を提案しています。学習が完了した後は、少量のラベル付けされたデータを使用して、特定のタスクに特化した予測ヘッドを学習させることが可能です。
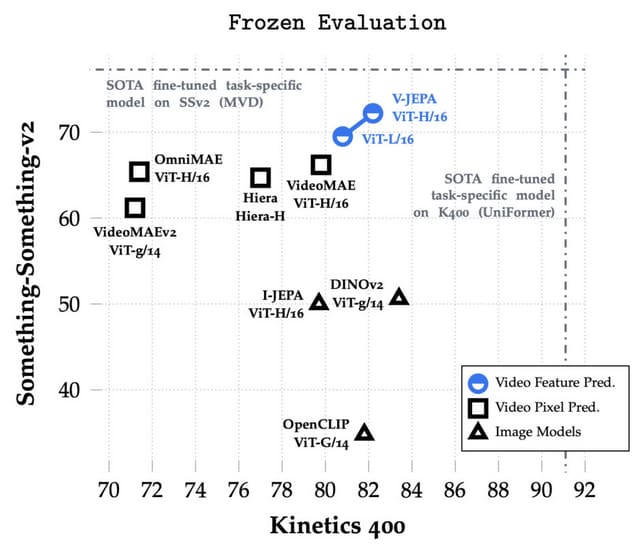
この柔軟なアプローチにより、訓練とサンプル効率が最大6倍向上し、実験結果として、ビデオのみで訓練された最大のモデルであるViT-H/16は、Kinetics-400で82.0%、Something-Something-v2で72.2%、ImageNet1Kで77.9%を達成しました。これらの成果は、時間的なビデオ解析の複数の側面において、これまでの主要なビデオ理解モデルと競合するか、それを超えるものです。

V-JEPA: Video Joint Embedding Predictive Architecture
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, Nicolas Ballas
Paper | GitHub | Blog
Google、最大100万トークンを処理できる「Gemini 1.5」を発表
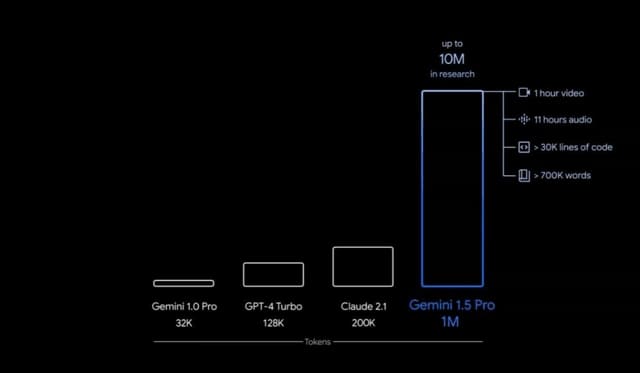
Gemini 1.5の中規模マルチモーダルモデルと位置付けた「Gemini 1.5 Pro」を発表しました。このモデルは、標準で12万8000トークンのコンテキストウィンドウを搭載しており、一部の開発者と顧客企業に向けて、AI StudioとVertex AIを通じて、限定プレビューとして最大100万トークンが提供されます。
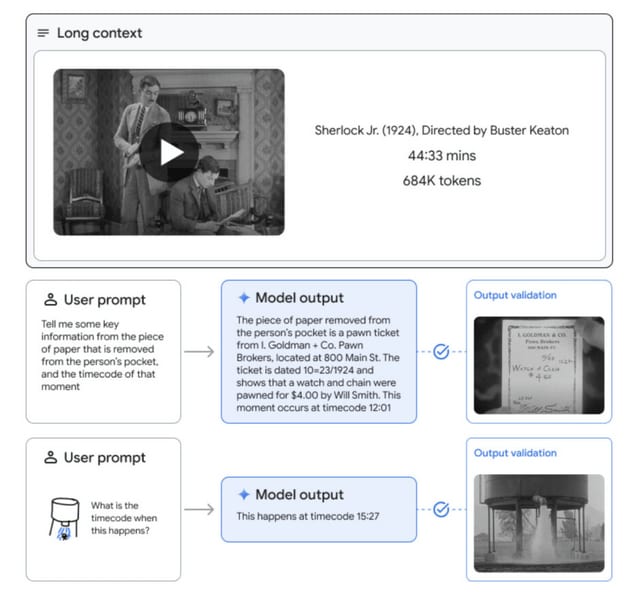
Gemini 1.5 Proは、長文コンテキストの情報検索タスク、長文書のQA(質問応答)、長時間ビデオのQA、長文コンテキストの自動音声認識(ASR)などにおいて最先端の性能を向上させ、幅広いベンチマークでGemini 1.0 Ultraの最先端のパフォーマンスに匹敵するか、それを上回ります。
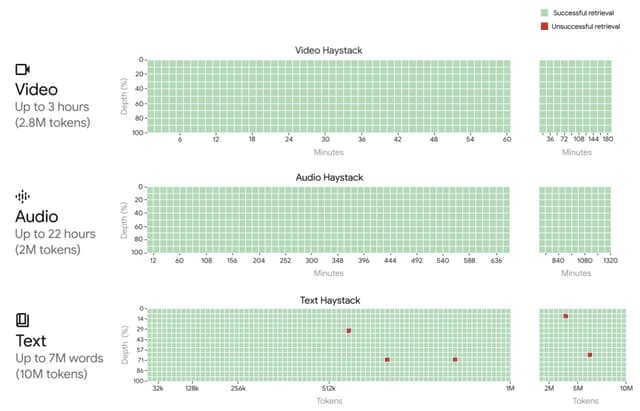
Gemini 1.5 Proの長文コンテキスト能力の限界を調査したところ、1000万トークンまでの情報検索をテスト的に実現しており、Claude 2.1(20万)、GPT-4 Turbo(12.8万)などの既存モデルに対して世代を超えた進歩を遂げています。また、1時間の動画、11時間の音声データ、3万行以上のソースコード、70万語のテキストなどの入力も一度に処理できることを実証しています。
Gemini 1.5 Proは、MoE(Mixture-of-Experts)を採用しており、このアーキテクチャを用いることで、特定のタスクに最適な計算資源を動的に割り当てることができ、より効率的に高度なタスクを処理できます。Gemini 1.5 Proは、数百万トークンのデータの中から特定の情報を正確に取り出す(リコールする)能力が非常に高く、また、新しい言語を学習するなど、以前のモデルにはない能力も持っています。

Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Google Gemini Team
Paper | Blog
LoRAを上回る効率的な新しい微調整方法「DoRA」、モデルの重みを「大きさ」と「方向」に分解し微調整
パラメータ効率の高い微調整方法として「LoRA」という手法がその単純さと効果のために人気があリますが、LoRAと従来のフル微調整(Full Fine-Tuning、FT)との間には学習能力の差が存在します。
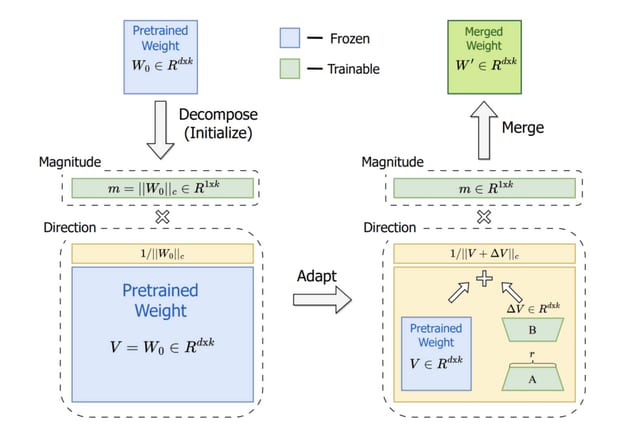
このギャップを埋めるため、本研究では事前訓練されたモデルの重みを「大きさ」と「方向」の2つの成分に分解し、それぞれを微調整することで効率的な微調整と高速な推論を両立させる新しい方法「Weight-Decomposed Low-Rank Adaptation」(DoRA)を提案しています。重みを分解することにより、微調整の過程をより細かくコントロールしやすくし、訓練可能なパラメータ数を最小限に抑えることができます。
この手法では、特に方向の更新にLoRAを活用し、訓練可能なパラメータの数を効率的に最小化します。方向成分とは別に、大きさ成分も微調整を行うことにより、モデルの出力に対する信頼度や強度の調整が可能になり、より適切な学習が実現されます。微調整を終えた後、更新された重みの成分を再統合します。DoRAはLoRAの学習能力と訓練の安定性を向上させる一方で、推論時のオーバーヘッドを発生させず、FTに似た学習行動を示します。
DoRAは自然言語処理(NLP)から視覚言語タスクまで、さまざまな下流タスクやモデルアーキテクチャにわたってLoRAを一貫して上回る性能を発揮します。特に、常識推論や視覚指示チューニングタスク、画像やビデオの理解などにおいて優れた結果を達成しました。
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen
Paper | GitHub
AI生成の巨大ペニスを生やしたネズミ画像、査読付き科学誌の論文に載ってしまい科学界困惑。学術的にもデタラメ
生成AIグラビアをグラビアカメラマンが作るとどうなる?第18回:バレンタイン編。ComfyUIの環境を整える (西川和久)

