
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第37回目は、生成AI最新論文の概要5つを紹介します。
YouTube広告を16倍速であっという間に終わらせるChrome拡張が公開、広告ブロック警告を回避
生成AI論文ピックアップ
24GBメモリの消費者向けGPUでも大規模言語モデルをゼロから事前学習できる可能性を示した手法「GaLore」、Metaなどが発表
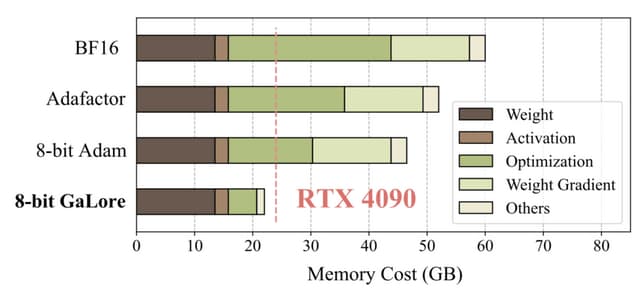
現在、LLMをゼロから学習するには、大容量のメモリを搭載したGPUが必要で、膨大な計算リソースを消費します。LLaMA 7Bモデルをゼロから学習するには、少なくとも58GBのメモリが必要とされています。ファインチューニング時のメモリ要件を減らす手法(例えばLoRA)は大きく進歩していますが、LLMの事前学習における有効性は限定的です。
この障壁を克服し、LLMの学習全体を通してメモリを大幅に削減する手法「Gradient Low-rank Projection」(GaLore)を考案しました。GaLoreは、完全なパラメータ学習を可能にしつつ、一般的なLoRA手法よりもメモリ効率のよい学習を実現します。
LLaMA 1Bと7Bのアーキテクチャを使い、最大19.7Bトークンの大規模なC4データセットで事前学習実験を行った結果、GaLoreはオプティマイザのメモリ使用量を最大65.5%削減しつつ、完全ランクの学習と同等の効率と性能を達成しました。
さらに8ビットの最適化手法と組み合わせることで、オプティマイザのメモリを最大82.5%、訓練全体のメモリを63.3%削減できました。また、事前学習済みのRoBERTaをGLUEタスクでファインチューニングした際にも、LoRAと同等以上の性能を達成しました。
特筆すべきは、7BパラメータのLLaMAモデルを、24GBメモリの民生用GPU(NVIDIA RTX 4090)上で、モデル並列化やアクティベーションのチェックポイント、オフロードなしでゼロから学習できる可能性を示した点です。ただし、24GBメモリのGPU1台で7Bモデルを事前学習するのにどの程度の時間を要したかなどの詳細については言及されていません。

GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
Paper | GitHub
1枚の画像から3Dモデルを高速生成するAI「TripoSR」、Stability AIなどが開発
TripoSRは、Stability AIとTripo AIの研究者らによって開発された、1枚の画像から3Dオブジェクトを高速に生成するモデルです。TripoSRは、Transformer構造を活用したLRMネットワークをベースとしながら、データ処理やモデル設計、学習テクニックに様々な改良を取り入れたモデルです
このシステムは、事前に訓練されたビジョントランスフォーマーモデルを使用して写真から特徴を読み取る部分、その情報を3D空間にマッピングすることで画像の情報を3D形状に変換する部分、そしてNeRFを基にして、3Dオブジェクトの色や密度を予測することで3D形状を詳細に作り上げる部分の3つから成り立っています。
TripoSRは、GSOとOmniObject3Dの2つのデータセットを用いて、他の最先端技術と比較されました。結果として、形状とテクスチャの再構成において、TripoSRは既存の方法よりも顕著に優れた結果を示し、オブジェクトの細かいディテールまで高い精度で捉える能力を示しました。また、NVIDIA A100 GPU上で単一画像から3Dメッシュを生成するのに約0.5秒という高速性も実証しました。


TripoSR: Fast 3D Object Reconstruction from a Single Image
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, Yan-Pei Cao
Paper | GitHub | Demo | Model
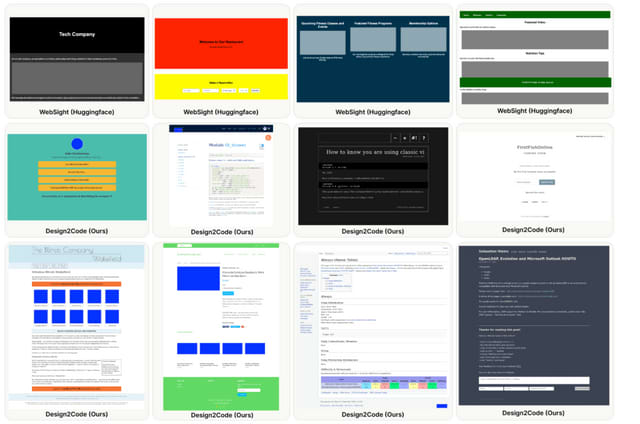
Webページのスクリーンショットからコードを生成するAI「Design2Code」
スタンフォード大学、ジョージア工科大学、Microsoft、Google DeepMindに所属する研究者たちは、Webページのスクリーンショットからコードを生成するモデル「Design2Code」を開発しました。
このプロジェクトでは、実世界のウェブページ484件を選定し、これらをテストケースとして使用します。また、これらのスクリーンショットを基に、参照Webページを正確に再現するコードがどれだけ効率的に生成できるかを評価するための自動評価基準を開発しました。この自動評価に加えて、詳細な人間による評価も実施されました。
研究チームは、様々なマルチモーダルモデルをテストし、GPT-4VとGemini Pro Visionの有効性を確認しました。さらに、Gemini Pro Visionと同等の性能を持つオープンソースのDesign2Code-18Bモデルを微調整しました。
人間による評価と自動評価基準の結果から、GPT-4Vがこのタスクにおいて最も優れた性能を示すことが明らかになりました。評価者は、GPT-4Vによって生成されたWebページの49%が元の参照を置き換えるに足りる品質であると判断し、64%が元の参照よりも優れて設計されていると評価しました。

Design2Code: How Far Are We From Automating Front-End Engineering?
Chenglei Si, Yanzhe Zhang, Zhengyuan Yang, Ruibo Liu, Diyi Yang
Project | Paper | GitHub
さまざまなテストでGPT-4を超える、Anthropicの新型LLM「Claude 3」
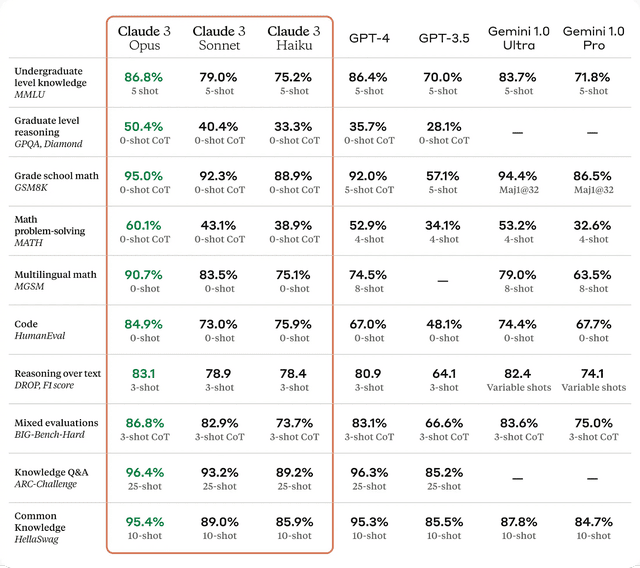
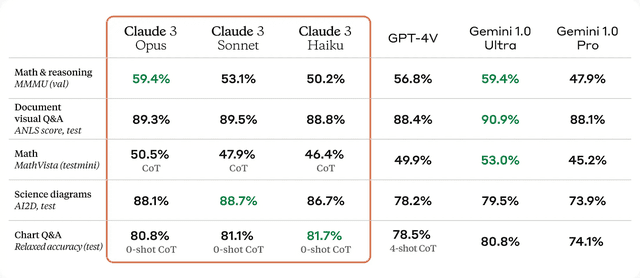
Anthropicが新たに発表した「Claude 3」は、大規模マルチモーダルAIモデルファミリーの最新版です。Claude 3ファミリーには、最も高性能な「Opus」、性能と速度のバランスが取れた「Sonnet」、最も高速かつ低コストの「Haiku」の3つのモデルが含まれています。いずれのモデルも画像処理・分析機能を備えたマルチモーダルモデルとなっています。また、英語以外の言語での流暢さも向上し、グローバルな利用シーンに適したモデルとなっています
Claude 3は数学、コーディング、長文処理、マルチモーダルタスクなどのベンチマークで高い性能を示し、新たな基準を打ち立てました。HaikuはClaude 2と同等以上の性能を純粋なテキストタスクで発揮し、SonnetとOpusはそれを大きく上回りました。特にOpusは、GPQA、MMLU、MMNUなど多くの評価で最先端の結果を達成し、多くのタスクでGPT-4と同等以上の性能を示しました。
知識のカットオフは2023年8月で、一般ユーザー向けのClaude.ai、Claude Proや、企業向けのAnthropic API、Amazon Bedrock、Google Vertex AIなどで提供します。Claude 3モデルは、少なくとも100万トークンに及ぶ長大なコンテキストを扱えるといいますが、実際の製品としては20万トークンまでのコンテキストウィンドウが提供されます。

The Claude 3 Model Family: Opus, Sonnet, Haiku
Anthropic
Project | Paper | Blog
画面を見てキーボードとマウスを自律的に操作するAI「CRADLE」、トリプルAタイトルで実証
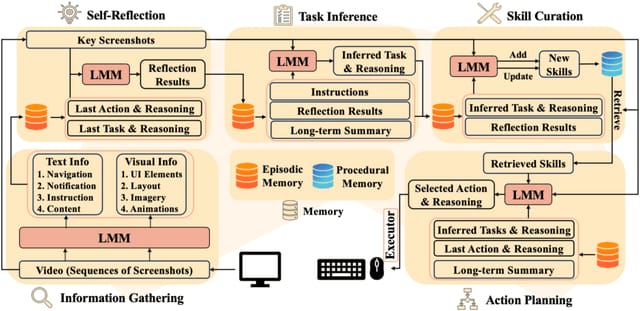
CRADLEは、汎用人工知能(AGI)の実現に向けて、コンピュータを人間のように操作できる汎用AIエージェントを開発するためのフレームワークです。画面の画像とオーディオを観測として受け取り、キーボードとマウス操作を出力として生成することで、どのようなコンピュータタスクもマスターできるエージェントの構築を目指します。
CRADLEフレームワークは、情報収集、内省、タスク推論、スキルキュレーション、アクション計画、メモリの6つの主要モジュールで構成されており、これらが連携することで、複数モダリティの情報を理解し、過去の経験を振り返りながら、タスクに関連する最適なスキルを生成・更新し、具体的なキーボード・マウス操作を計画することができます。
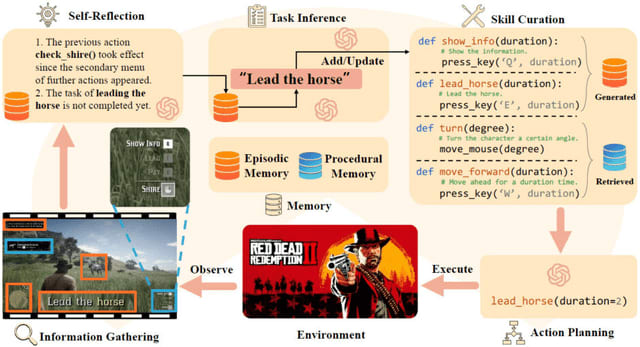
CRADLEフレームワークを複雑なAAAゲーム「Red Dead Redemption II」(RDR2)に適用し、ゲーム内のAPIやステータスにアクセスせずに、画面の画像のみを観測として使用し、キーボードとマウス操作を出力としてゲームを制御しました。
事前知識やリソースへの依存を最小限に抑えつつ、チュートリアルから学習し、家の探索、武器選択、乗馬、戦闘など、多様なタスクを自律的にこなし、初心者プレイヤーが40分程度かかるメインストーリーのミッションを完了しました。また、キャンプから町の雑貨店まで移動し、物資を調達するオープンワールドでのミッションも実行しました。

Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Weihao Tan, Ziluo Ding, Wentao Zhang, Boyu Li, Bohan Zhou, Junpeng Yue, Haochong Xia, Jiechuan Jiang, Longtao Zheng, Xinrun Xu, Yifei Bi, Pengjie Gu, Xinrun Wang, Börje F. Karlsson, Bo An, Zongqing Lu
Project | Paper | GitHub
生成AI「Stable Diffusion」の基本から最新技術の使い方まで。グラビアカメラマンが教える、生成AIグラビア実践ワークショップ(第6回)を3月22日開催。参加者募集します

