by 森山 和道

東京工業大学 学術国際情報センター(GSIC)は、次世代スパコン「TSUBAME 4.0」を2024年4月1日にすずかけ台キャンパスで稼動開始した。前世代に比べて半精度演算で20倍の理論ピーク性能を持ち、AIやコンバージェンス/サイエンス(総合知/科学の収斂)に活用される。4月17日には「TSUBAME4.0」の導入/運用を記念した披露式と見学会が、横浜の東工大すずかけ台キャンパスにて開催された。
「TSUBAME」とは東工大のスパコンシリーズに付けられている名称で、元々は「Tokyo-tech Supercomputer and UBiquitously Accessible Mass-storage Environmet」の略。2006年4月に稼働開始した「TSUBAME1.0」以来、国内外の産学官の研究開発を支えてきた。
TSUBAMEシリーズは以前からNVIDIAのGPUを活用してきた。最新の「TSUBAME4.0」はNVIDIA Hopperアーキテクチャに基づく「NVIDIA H100 TensorコアGPU」をさらにスパコン向けにチューニングした製品を採用。

理論演算性能は主に科学技術計算で利用される64bitの倍精度で66.8PFLOPS(ペタフロップス、1PFLOPSは1秒間に1,000兆回の計算)、人工知能など高速な演算で利用される16bitの半精度においては952PFLOPS。これは国内の研究/教育機関のスパコンの中ではスーパーコンピュータ「富岳」に次ぐ2位相当となる。
x86_64アーキテクチャのCPUとCUDA対応GPUを用いることで前世代「TSUBAME3.0」からの継続性を重要視するとともに、5.5~20 倍の性能向上、利用しやすさの向上を果たした。

「TSUBAME4.0」は学内研究者だけでなく、学際大規模情報基盤共同利用・共同研究拠点(JHPCN)や革新的ハイパフォーマンス・コンピューティング・インフラ(HPCI)などの共同利用プログラムを通じて学外研究者や企業研究者などに活用される。さらに2024年10月の統合により誕生する東京科学大学においても「コンバージェンス・サイエンスの展開」に不可欠な計算資源インフラとなることを狙う。

「TSUBAME4.0」の概要

計算ノードにはHPE Cray XD665サーバーを240台採用。1台あたりのプロセッサは第4世代AMD「EPYC 9654」(96コア)を2基、GPUは「NVIDIA H100 SXM5 96 GiB HBM2e」」を4基。メインメモリはDDR5-4800 768GiB。CPUとGPUは約20℃の冷却水により、直接水冷される。そのほかのノード内部品は背面ドア内で冷却水と熱交換された空気を用いて冷却する、水冷/空冷のハイブリッド冷却方式。




高速ネットワークインターフェイスはInfiniBand NDR200 200 Gbを4ポート搭載。ストレージシステムはローカルに1.92TB NVMe SSD、共有ストレージは「HPE Cray ClusterStor E1000」を搭載している。計算ノード及びストレージシステムはInfiniBandによる高速ネットワークに接続され、SINET6を経由し100Gbpsの速度で東工大すずかけ台キャンパスから直接インターネットに接続される。

システム性能は倍精度で66.8PFLOPS(TSUBAME3.0 比で5.5 倍)。半精度では952PFLOPS (TSUBAME3.0比で20倍)。共有ストレージ容量はHDD部で44.2 PB(TSUBAME3.0比2.8 倍)、SSD部で327TB(新規)。

スパコンをパソコンのように使いこなす未来の計算科学者を育成

2時間に渡って行なわれた披露式では、まず東工大 学術国際情報センター長の伊東利哉氏が「設置場所が大岡山からすずかけ台に変わった。多くの困難を乗り越えて調達にこぎつけた。半導体不足と円安で目標指標に到達するのは困難だった。辛抱強く交渉して今日にこぎつけた。みなさんのご支援に感謝する。共同研究も積極的に支援していく」と式辞を述べた。

開会挨拶は東工大学長の益一哉氏が行なった。益氏は「東工大は本年には東京医科歯科大学と統合して『東京科学大学』(略称 科学大)として新たなスタートを切る。尖った研究とコンバージェンスサイエンスを強く推進する。リサーチインフラの需要が高まっており、TSUBAME4.0は気象や物性科学、AIなどの研究はもちろん、生成AI、地球環境科学など融合学術領域においても重要な役割を果たすと期待している。
特徴はGPUを大幅に取り入れたスパコンであること。東工大ではその歴史は長い。運用経験の蓄積を続けてきた。高性能を発揮するためのトポロジー設計、UI開発など継続的な努力を重ねてきた。各企業との共同開発の結果として、AI向け性能では従来の3.0の20倍を誇る4.0が実現された」と述べた。
そして「東工大だけではなく、HPCIなどの枠組みを使って学外からも利用できる。産官学、国際連携に活用される。新入生もキャンパスライフを通じて日常的にTSUBAMEを活用できる。スパコンをPCのように使いこなす未来の計算科学者を育成しようとしている。必要不可欠なプラットフォームとしてユーザーを結びつけるハブとなり、国際競争力強化を力強く支援する」と語った。
計算基盤には、それ自体にもサイエンスとしての価値がある

続いて来賓挨拶は、まず「半導体で興奮する性質がある」という文部科学省 研究振興局参事官(情報担当)付 計算科学技術推進室長の栗原潔氏が「我が国全体のためにもこのような基盤整備がなされたことにお祝いと感謝を申し上げる。
TSUBAME1.0で採用されたクリアスピードは当時、メディアでも話題になった。ロマンがあるし、今では当たり前になったヘテロジーニアスなシステムには東工大は先駆的に取り組んでシステムを構築してきた。HPCの開発には使われるだけではなく、宇宙科学におけるロケットのように基礎研究、サイエンスとしての価値もある。常に東工大が先を走っていて国はその後を追っている。政府としても着実な継続した支援を行ないたい」と語った。

情報・システム研究機構 国立情報学研究所長の黒橋禎夫氏は「生成AI、マシンラーニング、学術全般の発展にスパコン性能向上が貢献しているのは間違いない。東工大は常に最新技術を取り入れた計算サービスを提供しており、HPCを支える重要な役割をしてきた。特にGPUを初期段階から提供してきたことは世界的にも先駆的な取り組みだった。
当初から『みんなのスパコン』というコンセプトを掲げてきて、さらに普及を広げ学術分野の発展を促してきたといっても過言ではない。国立情報学研究所においても4月に大規模言語モデル研究開発センターを設置した。連携と協力について協定を結び、本日付けでプレス発表も行なった」と紹介した。

2010年まで東工大に在籍していた東京大学 情報基盤センター長の千葉滋氏は「TSUBAMEのアーキテクチャは現在主流となったアーキテクチャの先駆けだった。少なくとも国内では元祖だった。挑戦的なマシン。小さなプロトタイプスパコンから研究を積み重ねた結果として大学のスパコンになったことは非常にのぞましいのではないか」と過去を振り返りながら祝辞を述べた。10年以上前には大学事務から電力削減が呼び掛けられた時期もあったという。
スパコン設計は単なるシステム設計ではなく夢の実現

開発事業社からもHewlett Packard Enterprise Company SVP &GM, HPC & AI Go-To-MarketのSuresh Badu氏、日本ヒューレット・パッカード合同会社 HPC&AI 事業統括本部 執行役員 統括本部長 根岸史季氏、NVIDIA合同会社 エンタープライズ事業本部長 井﨑武士氏が登壇し、祝辞を述べた。
まず、計算ノードやストレージ開発を行なったHewlett Packardのスレッシュ・バドゥ(Suresh Badu)氏は技術パートナーたちへの感謝を述べ「スパコンを設計するたびに、システムを設計しているのではなく、誰かの夢を実現している。無限の可能性と想像力、それと技術を調和させていきたい。数年後にはTSUBAME5.0でお会いしたい」と述べた。

日本ヒューレット・パッカードの根岸史季氏は「TSUBAMEには3代に渡って関わらせてもらえた。ユニークなコンセプトでベンダーの立場からすると無理難題。使いやすさと革新性は相反するので両立は難しい。最新トレンドを取り入れながらサイエンスを動かすには確立した手法が必要でバランスが重要。サイエンスに基づいた骨格がしっかりしたものをサポートしながら新しいドメインもサポートする。さらにみなさんに使いやすいものにする。目指すべきものはそこ。課題のお手伝いができるのは嬉しい」と述べた。

GPU環境構築に貢献したNVIDIAの井﨑武士氏は「2008年に世界初のGPU活用スパコンTSUBAME1.2が出てきてさまざまな科学研究が、CUDAによって加速されてきた。それが現在のCUDAコミュニティ活性化、研究につながっている。
昨今は生成AIに計算パワーが必要とされている。時代の進化とともに性能は急激にアップしている。技術の先端を東工大には使ってもらっている。医学工学連携も進んでいく。科学技術の発展に寄与することを祈念している」と祝辞を述べた。
スマホやWebブラウザからも利用可能、「もっとみんなのスパコン」に

TSUBAME4.0の概要説明は学術国際情報センター教授の遠藤敏夫氏が行なった。TSUBAMEはこれまで「みんなのスパコン」をキャッチフレーズにしてきたが、4.0は「もっとみんなのスパコン」として、ビッグデータ解析やAI・ディープラーニングなどに用いられる。

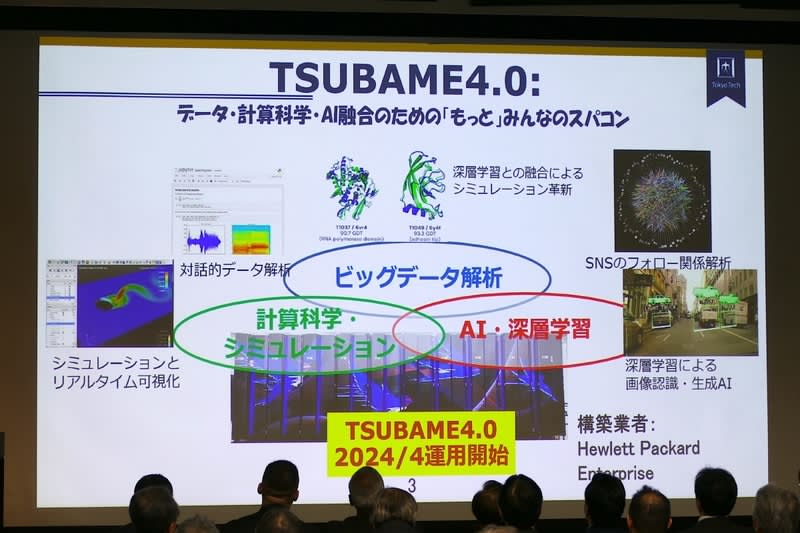
ハードウェア面ではNVIDIAのGPUである H100を960枚採用。半精度の演算性能では20倍、952PFLOPSを実現した。x86CPUを使うことで現在のAIおよびHPCのデファクトスタンダード環境を利用できるソフトウェアの継続性を重視。同時に「みんなのスパコン」としての使いやすさも重視し、Webブラウザからもインタラクティブ利用を可能にした。初学者から専門家まで、さまざまな利用資源サイズに対応する。

計算ノードはHPE Cray XD665を240台。ストレージとしてはTSUBAMEシリーズでは初めてのSSDベースのストレージも採用した。計算ノードのCPUは192コアのAMD PPYC 9654 ×2。GPUはNVIDIA H100×4。従来のTSUBAMEユーザーにとっては連続性がある構成となっている。

GPUについてはH100 SXM5 94GBモデルを使っている。速度においてトレードオフはあるがメモリが大きく、LLMを含む大規模モデル学習には使いやすい構成となっている。CPUはAMD EPYC 9654で、x86 CPUの中ではコア数は96と最大。全240ノード全体合計では46,080コアとなる。


「みんなのスパコン」としては使いやすさを追求した。従来のスパコン利用ではSSHログインとジョブ処理投入が必要だが、今はクラウドなどWeb上での計算資源利用が普及している。そこで従来方式に加えて、Webブラウザでも直接TSUBAMEを活用可能にした。スパコンユーザーの新規発掘も狙う。

さまざまな利用資源サイズにも対応する。初学者から専門家までさまざまなユーザーの多様な規模のジョブリクエストに応じて、動的にリソースを振り分ける。
たとえば多数のGPUとコアを必要とする環境に対しても、1GPU、あるいは0.5GPUが必要な環境に対しても計算機を動的・論理的に割り振って提供する。ノートPCでも実行できるような環境であっても、作っては消し、作っては消しといった利用が可能になるという。このような取り組みについては、メーカーなどとの連携で3.0のころから一部取り組みは始めておいたものだと紹介した。

なお、今回 TSUBAME4.0 における初めての試みとして、ラックデザインの公募を行なった。新しいスパコンが持つさまざまな可能性や用途の広がりをイメージし、4羽の「つばめ」が自由な流線を描きながら、どこまでも無限に広がる世界を羽ばたいていく様子のデザインが選定され、そのデザインに合わせてラックを施工したという。


中分子創薬でのスパコン活用

さらに続いて学術講演として、教授2人が講演を行なった。まず「スパコンが加速する中分子創薬の潮流」と題して情報理工学院 情報工学系の秋山泰教授が講演を行なった。秋山氏は2006年以降、歴代のTSUBAMEを活用してきた。ユーザーの1人としても「TSUBAM4.0はどうなるのかと気を揉んでいた」という。

私たちが飲んでいる医薬品は一般に低分子医薬品だ。それに対して抗体医薬品という大きな分子の医薬品も登場している。中分子創薬とはその中間、アミノ酸が2個から50個ほどつながったぺプチドや、核酸医薬品のことである。低分子と抗体の良いところどりをしており、製造コストも下げられるという。


自然界からとられたペプチドもあるが、秋山氏らは、すべての薬剤設計の標準的骨組みとして特殊環状ペプチド分子を使おうという研究を進めている。低分子では狙えないPPI阻害効果などが狙える。安価であり、経口投与や細胞膜透過が可能で、標準ブロックの組み合わせで作れるという。

ただし人体内での薬物動態には課題がある。血中での安定性が低く、早く分解されてしまう。また第2の問題としては細胞膜透過性がある。要するに、サイズが大きく細胞膜を透過しにくい。薬効が高い大型ペプチドほど細胞膜を通りにくい。

だが安価に製造できることから可能性は高い。そこでディープラーニングによる挑戦を行なった。マシンラーニングを使って予測モデルを構築する。数百から数千次元の特徴ベクトル、化合物のグラフ表現などのデータから訓練を行ない、体内持続性などの予測モデルを構築する。
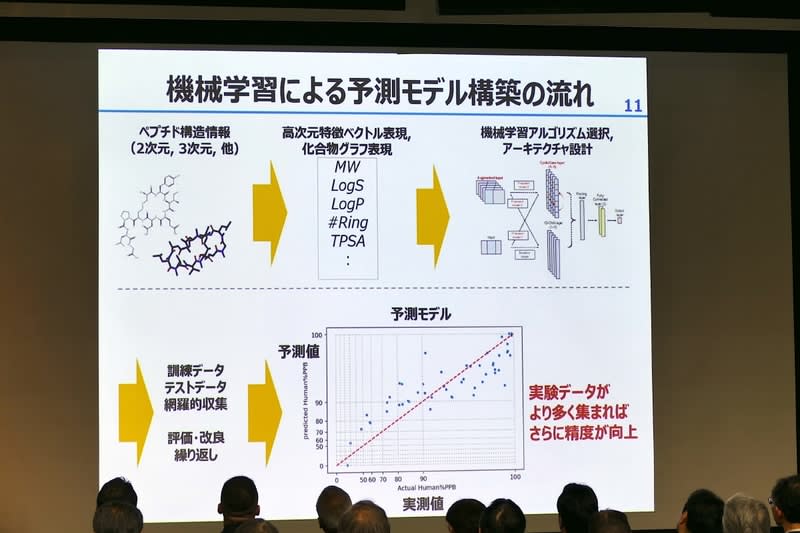
2022年にはデータ拡張などの手法を使って、体内持続性予測モデルを構築して発表した。さらに2023年には膜透過の予測モデルも発表した。


だがマシンラーニングだけでは、ペプチド化学修飾の多様性には対応しきれなかった。そこで分子動力学シミュレーションによる正面突破を目指した。秋山氏は「人類にペプチドの膜透過シミュレーションは可能なのだろうか」と題したスライドを示し、「そのくらいの距離感がある」と紹介した。フェムト秒単位で起こる分子同士の反応1ステップだけでも膨大な計算が必要で、そこからミリ秒単位までにはさらに膨大な計算を積み重ねなければならないからだ。


秋山氏らはGPUの活用、効率的サンプリング法、TSUBAMEの同時並列実行を組み合わせて、ある程度の結果を出すことに成功した。さまざまな位置での計算を同時並列実行するサンプリング法である「REUS」を使い、28個の別々の世界を作って計算を行ない、起きにくい状況をサンプリング。解析してエネルギー地形を計算。シミュレーションを回して収束させて膜透過率を定量的に推定した。


28個の世界にさらに温度の異なる世界を使って計算を実行させて、評価値を計算することで正確性を上げて、合成せずにTSUBAME上である程度の評価ができる仕組みを作り上げた。予測値と実験値の相関係数は0.8~0.9程度。

シミュレーションすることで、数値だけではなく、実際に分子間でどのような相互作用が起きているかも見ることができる。それによって、ペプチドをどのように変えると何が起きているのか、より深く理解できるようになったという。


今後はTSUBAME4.0を使えるようになるが、単純に計算させても能力を引き出すことはできない。性能を発揮させるにはGPUをうまく埋めることが必要になる。道具を使いこなすには、物理・化学・薬学だけではなく、新しいアーキテクチャを理解しているスパコン技術の専門家との協力がとても重要だと強調した。

今後、東京医科歯科大学と東工大の統合によって誕生する東京科学大学では、国内外の産業界とも連携し、中分子創薬の国際的な創薬コンソーシアム立ち上げを目指す。TSUBAME4.0は産業利用もできるので、そのパワーが活用されることを期待しているという。
東工大・産総研による大規模言語モデルSwallow

学術国際情報センター教授の横田理央氏は「東工大・産総研による大規模言語モデルSwallow」と題して講演。横田氏はまず、OpenAIのChatGPTと、GoogleのGeminiの性能について概略を紹介し、専門家が予想していたよりも多くの機能が早く実現されていると述べた。

そして近年の生成AIの動向や、パラメータ数に応じて性能が向上する「スケーリング則」などを紹介し、「MicroSoftがOpenAIに10億ドルを投資したのは2019年6月。テキストから画像に移ったのは最近の話ではない。中国では2022年8月には130Bのモデルが発表されている。OpenAIのChatGPT発表は2022年11月で、公開後2カ月で1億ユーザーを突破した」と振り返った。

東工大・産総研は2023年12月にMetaの「LLaMA2」をベースにした「Swallow」を公開。3月にはSwallow-MS、Swallow-MXを公開した。
今では非常に多くの会社が取り組んでいるディープラーニングの大規模化だが、近年、特に大きな予算が割かれるようになった。投資規模は今では2年ごとに100倍となっている。だが、どこまでも予算がかけられることはありえない。
OpenAIの「GPT-4」は当時8,000ドルしたGPUを25,000枚、90日間連続で使い続けたと言われている。これが「とんでもない規模のコストをかけるきっかけとなっている」という。

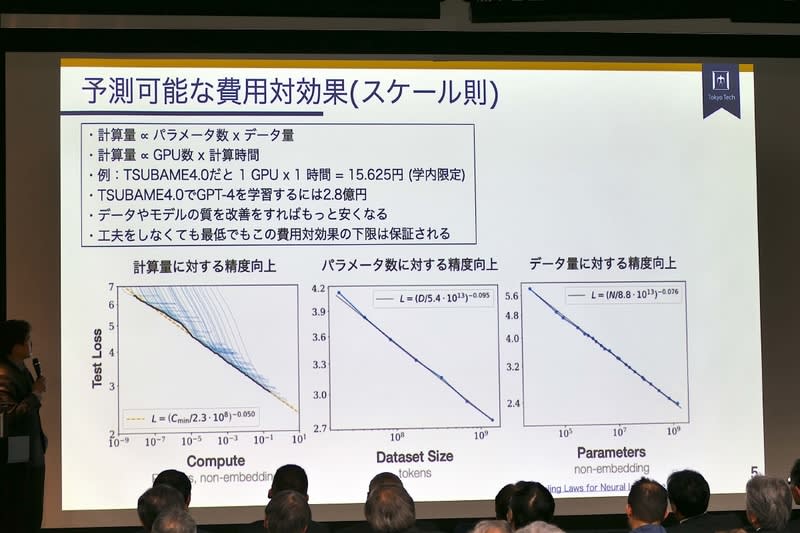
ではなぜそんなに予算が割かれるようになったのか。パラメータ数とデータ量をかけると計算量になり、大きなモデルを学習するためにはそれに比例する計算量が必要となる。ハードウェアから見ると長時間スパコンを占有する必要がある。
たとえばTSUBAME4.0だと学内価格では1GPUを1時間使うと15.625円なので、単純に計算するとGPT-4の学習のためには、およそ2.8億円かかることになる。OpenAIはMicrosoftから1,000億円の投資を受けてGPTを開発したと言われているので、破格の値段だ。
データやモデルの質を改善すれば、もっと安くすることができる。スケーリング則はあくまで「性能の下限」を示すものなので、同じパラメータ数でもモデル性能やデータの質を上げれば性能は上がる。
TSUBAME4.0では分散並列処理が可能だが、多くのGPUを協調させて使うためにはGPU間の通信が重要だ。横田氏らはその部分を担当して、数百GPUを同時に使って1カ月も学習させる際の高速化/並列化/頑健化を担当して、「Swallow」を構築した。

研究グループではMetaがオープンソースとして公開している「Llama2」に日本語を継続して学習させることで、Metaが英語で学習した知識を使って日本語で会話できるようにした(リリース)。データの収集と精製は岡崎研究室が担当し、CommonCrawlのデータからフィルタリングを行なって学習させた。データのフィルタリングはURL、テキスト情報、重複などをもとに行なった。


分散並列学習については、一長一短ある手法を組み合わせて巨大な言語モデルを高速で学習させたという。ベンチマーク性能では善戦。今後さらなる向上を目指す。ユーザーの評判も良いと紹介した。
LLMを作るには今までスパコンを使って作られてきたあらゆるアプリケーションよりもコストが必要で、いかに綺麗なデータを精製するか、いかに高速で学習させるか、そのために手法開発が重要で、ユーザーの声も重視していると述べた。

