1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第46回目は、生成AI最新論文の概要5つを紹介します。
AIの新星ニューラルネットワーク「KAN」とは? LLMが“カンニング”して評価を盛ってた? など重要論文5本を解説(生成AIウィークリー)
生成AI論文ピックアップ
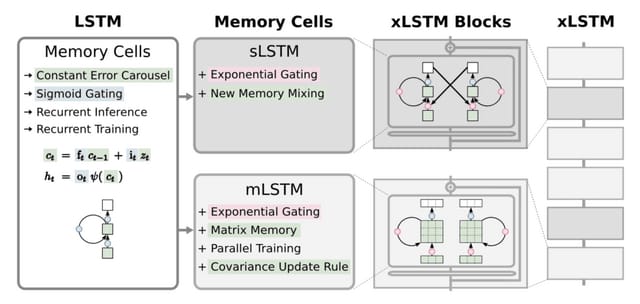
LSTMの進化形「xLSTM」登場。Transformerと同等かそれ以上の性能
LSTM(Long Short-Term Memory)の拡張バージョンである「xLSTM」について紹介しています。1990年代に開発されたLSTMは、様々なシーケンス関連タスクで成功を収めてきましたが、Transformerの技術の登場により、その位置は徐々に置き換えられつつあります。この状況を受けて、研究者らはLSTMのスケーリングと最新の技術を組み合わせて、その限界を克服しようと試みています。
xLSTMでは、主な改良点として指数関数的なゲーティングと新しいメモリ構造が採用されています。具体的には、xLSTMにはsLSTMとmLSTMの2つのタイプがあります。sLSTMはスカラーメモリを持ち、新しい情報の混合方法を提供します。一方、mLSTMは行列メモリを使用し、並列処理が可能です。
これらのsLSTMとmLSTMをブロックとして組み合わせ、積み重ねることでxLSTMのネットワークが構築されます。シンプルな設計ですが、最先端のTransformerやState Space Modelと同じかそれ以上の性能を出せることが実験でわかりました。
xLSTM: Extended Long Short-Term Memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, Sepp Hochreiter
Paper
Google、タンパク質を予測するモデル「AlphaFold 3」発表
Google DeepMindは最新版のタンパク質構造予測システム「AlphaFold 3」を発表しました。AlphaFold 3は、タンパク質だけでなく、核酸、低分子リガンド、イオン、修飾残基などを含む様々な生体分子の複合体構造を高い精度で予測することができます。
AlphaFold 3のアーキテクチャは、前バージョンのAlphaFold 2から大幅に進化しています。配列情報を処理するEvoformerの代わりにPairformerモジュールを導入し、アミノ酸に特化した座標系ではなく原子座標を直接予測するDiffusionモジュールを採用しました。これにより、任意の化学構造を柔軟に扱えるようになっています。
性能評価では、タンパク質-リガンド複合体の予測では最新のドッキングツールよりはるかに高精度で、タンパク質-核酸相互作用の予測では核酸特化型予測ツールよりはるかに高精度、抗体-抗原複合体の予測ではAlphaFold-Multimer v2.3よりも大幅に高精度を達成しました。
Accurate structure prediction of biomolecular interactions with AlphaFold 3
Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J. Ballard, Joshua Bambrick, Sebastian W. Bodenstein, David A. Evans, Chia-Chun Hung, Michael O’Neill, David Reiman, Kathryn Tunyasuvunakool, Zachary Wu, Akvilė Žemgulytė, Eirini Arvaniti, Charles Beattie, Ottavia Bertolli, Alex Bridgland, Alexey Cherepanov, Miles Congreve, Alexander I. Cowen-Rivers, Andrew Cowie, Michael Figurnov, Fabian B. Fuchs, Hannah Gladman, Rishub Jain, Yousuf A. Khan, Caroline M. R. Low, Kuba Perlin, Anna Potapenko, Pascal Savy, Sukhdeep Singh, Adrian Stecula, Ashok Thillaisundaram, Catherine Tong, Sergei Yakneen, Ellen D. Zhong, Michal Zielinski, Augustin Žídek, Victor Bapst, Pushmeet Kohli, Max Jaderberg, Demis Hassabis & John M. Jumper
Paper | Blog
Googleが“未来予知”する時系列予測AI基盤モデル「TimeFM」を開発。金融や気象、交通などの一歩先を予測
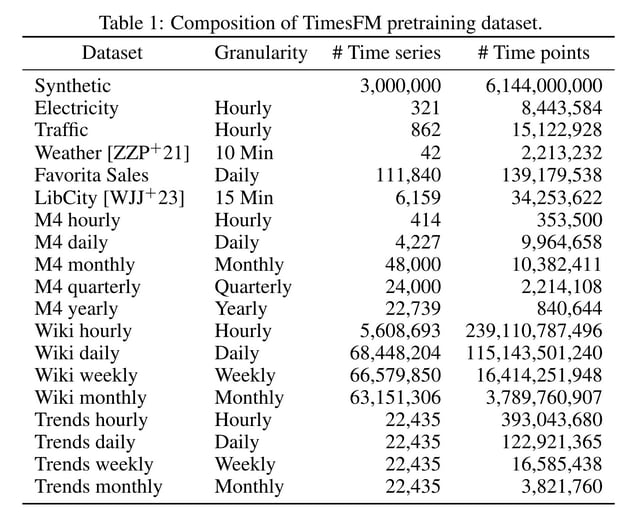
GoogleがTimeFM(Time Series Foundation Model)という時系列予測のための基盤モデルを開発しました。TimesFMは、多様な分野の時系列データを事前学習することで、特定の分野のデータでファインチューニングすることなく、ゼロショットで高精度な予測を可能にします。
TimesFMのアーキテクチャは、言語モデルと同様にTransformerのデコーダーのみで構成されていますが、時系列データに適した工夫が施されています。
学習には、Google検索トレンドのクエリ数時系列データ、Wikipediaの記事ごとの時系列データ、電力、交通、気象などの実データを使用しています。加えて、ARMAモデルや周期性、トレンドなどを組み合わせて生成した合成データも用意しており、これにより実世界では観測されにくいパターンもカバーしています。
TimesFMは、小売の需要予測、気象予測、交通予測、金融予測、電力需要予測などさまざまな分野での時系列予測タスクへの応用が期待されています。
評価実験では、複数のベンチマークデータセットを用いて、需要予測、気象、交通など様々な分野の時系列予測タスクでゼロショットの性能を評価しました。その結果、多くのデータセットにおいて、データセット毎に個別にチューニングした教師あり手法と同等以上の予測精度を達成することが分かりました。
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou
Paper | GitHub | Hugging Face | Blog
Llama3 70Bと同等の性能を示す、オープンソース大規模言語モデル「DeepSeek-V2」
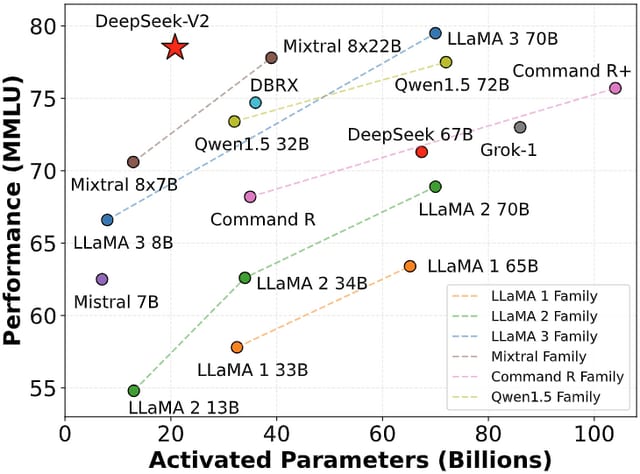
DeepSeekは、最新の大規模言語モデルDeepSeek-V2を発表しました。DeepSeek-V2は、合計2360億のパラメータを持ち、そのうち210億が各トークンに対して活性化されるMixture-of-Experts(MoE)アーキテクチャを採用しています。また、最大12万8000トークンの長い文脈の入力にも対応可能です。
DeepSeek-V2は、MLA(Multi-head Latent Attention)という技術で情報を圧縮することで、コンピュータの負担を減らしています。また、DeepSeekMoEという仕組みで、得意分野ごとに専門家のようなプログラムを作ることで、少ない計算リソースで賢くなることができました。
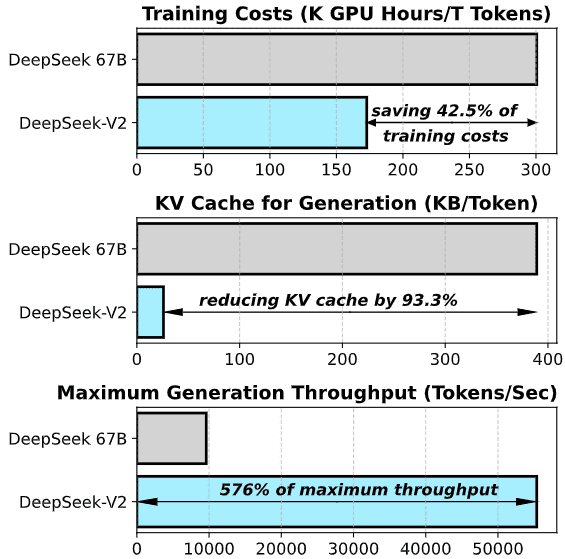
DeepSeek-V2は8.1兆トークンの大規模かつ多様なコーパスで事前学習されました。さらに、微調整と強化学習により、性能がさらに向上しています。DeepSeek-V2は、DeepSeek 67Bと比較して42.5%の学習コストを削減し、推論時のKVキャッシュを93.3%削減、最大スループットを5.76倍に向上させました。
評価実験の結果、DeepSeek-V2は210億のパラメータしか使わないにもかかわらず、英語と中国語の各種ベンチマークにおいてオープンソースモデル(DeepSeek 67B、Qwen1.5 72B、LLaMA3 70B、Mixtral 8x22Bなど)の中でトップクラスの性能を示しました。
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI
Paper | GitHub | Hugging Face
IBM、コーディング専用AIモデル「Granite Code Models」を開発
IBM Researchは、コーディングに特化したAIモデルファミリー「Granite Code Models」を開発しました。Granite Code Modelsは、3億から340億パラメータまでの様々なサイズのデコーダーのみのモデルで構成されており、コード生成、バグ修正、コードの説明とドキュメント化、リポジトリのメンテナンスなど幅広いタスクに対応できます。このモデルファミリーは、複雑なアプリケーションの最新化タスクから、デバイス上のメモリ制約のあるユースケースまで、幅広いアプリケーションに適しています。
事前学習用のコードデータは、GitHub Code Clean、StarCoderdata、GitHubの公開リポジトリとイシューなどの組み合わせから収集され、116のプログラミング言語に絞り込まれました。また、言語理解と数学的推論スキルを向上させるために、Stackexchange、CommonCrawl、OpenWebMath、StackMathQA、Arxiv、Wikipedia、FLAN、HelpSteerなどの高品質な自然言語データセットが選別されています。
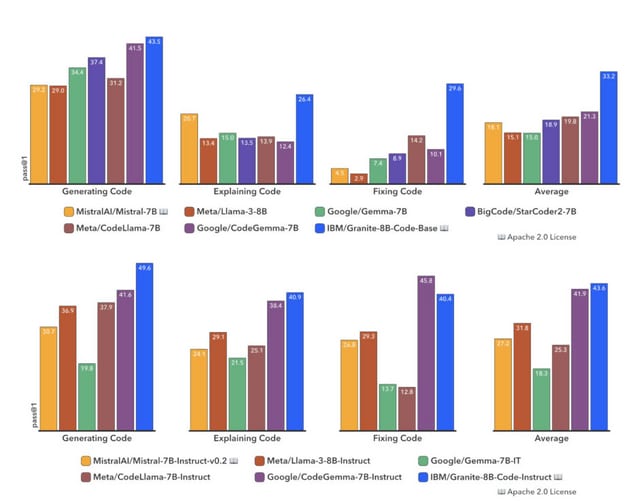
Granite Code Modelsは、HumanEvalPack、MBPP、RepoBench、ReCodeなどの包括的なベンチマークセットで評価されており、これらのベンチマークはコード生成、修正、説明、編集、翻訳など、さまざまなタスクをカバーしています。評価結果は、Granite Code Modelsが、CodeGemma、StarCoder2、Llama3など、最近リリースされた他のオープンソースモデルと同等またはそれ以上のパフォーマンスを示していることを明らかにしています。

Granite Code Models: A Family of Open Foundation Models for Code Intelligence
Mayank Mishra, Matt Stallone, Gaoyuan Zhang, Yikang Shen, Aditya Prasad, Adriana Meza Soria, Michele Merler, Parameswaran Selvam, Saptha Surendran, Shivdeep Singh, Manish Sethi, Xuan-Hong Dang, Pengyuan Li, Kun-Lung Wu, Syed Zawad, Andrew Coleman, Matthew White, Mark Lewis, Raju Pavuluri, Yan Koyfman, Boris Lublinsky, Maximilien de Bayser, Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Yi Zhou, Chris Johnson, Aanchal Goyal, Hima Patel, Yousaf Shah, Petros Zerfos, Heiko Ludwig, Asim Munawar, Maxwell Crouse, Pavan Kapanipathi, Shweta Salaria, Bob Calio, Sophia Wen, Seetharami Seelam, Brian Belgodere, Carlos Fonseca, Amith Singhee, Nirmit Desai, David D. Cox, Ruchir Puri, Rameswar Panda
Paper | GitHub | Hugging Face
作曲歌唱AI「Suno」、今からでも間に合う制作マニュアル。やり方がちょっと変わったので(CloseBox)
