
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第48回目は、生成AI最新論文の概要5つを紹介します。
作曲歌唱AI「Suno」、今からでも間に合う制作マニュアル。やり方がちょっと変わったので(CloseBox)
生成AI論文ピックアップ
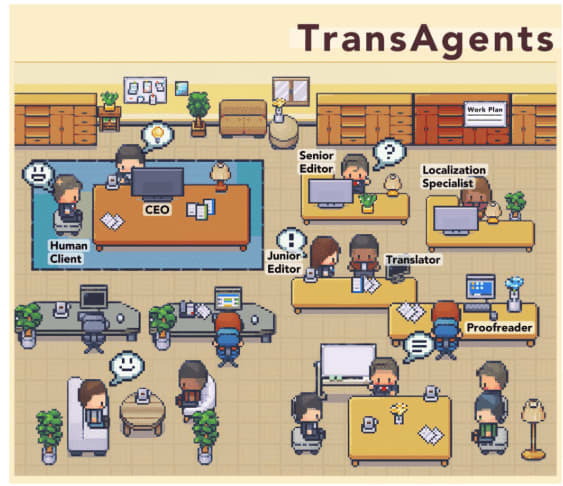
“文学作品”を翻訳する、実際の出版社を真似たAI会社「TransAgents」
近年、機械翻訳の分野では、大規模言語モデル(LLM)の発展により、翻訳品質が大幅に向上しています。しかし、比喩表現や文化的ニュアンスが多用される文学作品の翻訳は、いまだ大きな課題となっています。
この研究では、LLMを活用した新しいマルチエージェントフレームワーク「TransAgents」が提案されています。TransAgentsは、CEOや編集者、翻訳者、校閲など、実際の翻訳出版プロセスを模したエージェントたちが協調して翻訳を行うシステムです。
各エージェントは、GPT-4などのLLMをベースに構築されており、それぞれの役割に応じた能力を持っています。これにより、文学作品の複雑さに対処することを目指しています。
評価手法としては、「Monolingual Human Preference」(MHP)と「Bilingual LLM Preference」(BLP)という2つの新しいアプローチが提案されています。MHPでは、翻訳言語のモノリンガル話者が原文を見ずに翻訳を評価します。一方、BLPでは、高度なLLMが原文と翻訳を直接比較します。
実験の結果、機械翻訳の評価手法の一つであるd-BLEUスコアではTransAgentsが最も低かったものの、人間が書いた翻訳やGPT-4の翻訳よりも好まれる傾向にありました。特に、歴史的背景や文化的ニュアンスの理解が求められるジャンルで高い評価を得ました。
(Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts
Minghao Wu, Yulin Yuan, Gholamreza Haffari, Longyue Wang
Paper
任意のアスペクト比と高解像度の画像を効率的に認識できる大規模マルチモーダルモデル「LLaVA-UHD」
大規模マルチモーダルモデル(LMM)は、視覚を理解するために、画像を適切にエンコーディングすることが重要です。従来のLMMは、固定サイズかつ低解像度の画像しか処理できず、最近の研究でもその適応性、効率性、正確性に課題があります。この研究では、代表的なLMMであるGPT-4VとLLaVA-1.5を例に取り、その視覚的エンコーディング戦略に根本的な欠陥があることを明らかにしました。
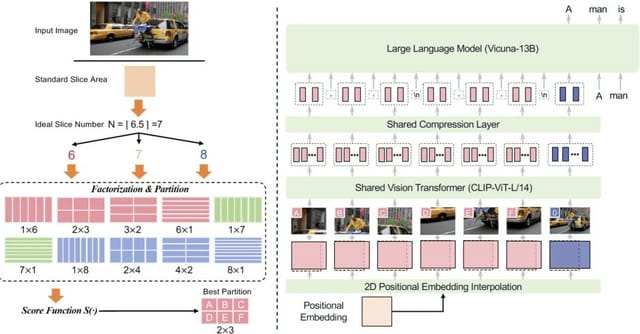
これらの課題に対処するため、LLaVA-UHDを提案しています。LLaVA-UHDは任意のアスペクト比と高解像度の画像を効率的に認識できるLMMです。LLaVA-UHDには3つの重要な要素があります。
1つ目は、ネイティブ解像度の画像を小さな可変サイズのスライスに分割し、効率的かつ拡張可能なエンコーディングを行う画像モジュール。2つ目は、視覚エンコーダから出力される画像トークンをさらに圧縮する圧縮モジュール。3つ目は、スライストークンを整理してLLMに伝えるためのモジュールです。
9つのベンチマークでの包括的な実験により、LLaVA-UHDは2~3桁多くのデータで学習された既存のLMMを上回ることが示されました。特にLLaVA-1.5をベースにしたモデルは、わずか94%の推論コストで6倍の解像度(672×1088)の画像をサポートし、TextVQAで6.4%、POPEで3.2%の精度向上を達成しました。この優位性は、より極端なアスペクト比の画像でさらに拡大します。
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Ruyi Xu, Yuan Yao, Zonghao Guo, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, Maosong Sun, Gao Huang
Paper | GitHub
GPT-4は投資先選びに活用できるのか? 企業の財務諸表を分析し将来の利益を予測
この研究では、大規模言語モデル(LLM)であるGPT-4を使用して、財務諸表を分析し、将来の利益の方向性を予測するタスクを行いました。
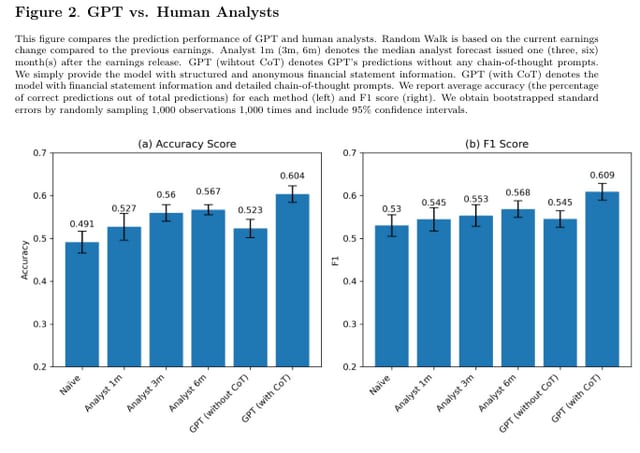
研究者らは、GPT-4に財務諸表を分析させる際、単純にタスクを指示するだけでなく、人間のアナリストが行うようなステップバイステップの分析プロセスを模倣するような指示を与えました。これにより、GPT-4は人間のような推論を行い、予測精度が大幅に向上しました。
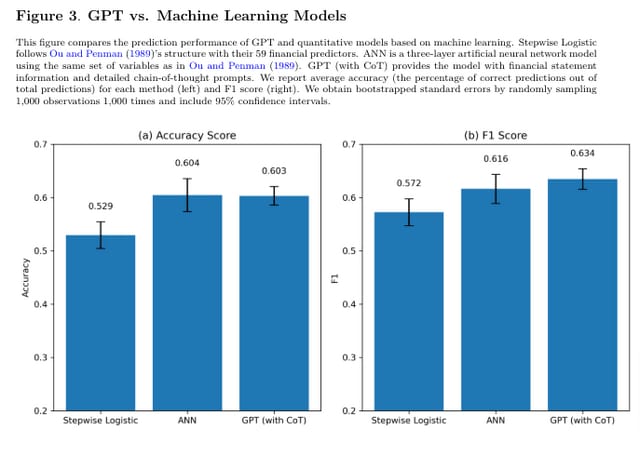
その結果、GPT-4は業界固有の情報を一切提供されていないにも関わらず、人間のアナリストの予測精度を上回る結果を示しました。またGPT-4の予測精度は、利益予測のために特化して訓練したモデルと同等であることも明らかになりました。
これらの結果から、GPT-4が生成した企業の将来見通しに関する洞察は、トレーニング時の内容に由来するものではなく、財務数値データから有意義な情報を抽出し、それに基づいて予測を行っていることが示唆されました。
最後に、GPT-4の予測に基づいて構築された投資戦略は、他のモデルに基づく戦略と比較して、より高いリターンとリスク調整後リターン(シャープレシオとアルファ)を示しました。これは、GPT-4による財務諸表分析が実務的にも価値があることを示唆しています。
Financial Statement Analysis with Large Language Models
Alex Kim, Maximilian Muhnm, Valeri V. Nikolaev
Paper
「Claude 3.0 Sonnet」が内部でどう考えているかをAnthropicが公開
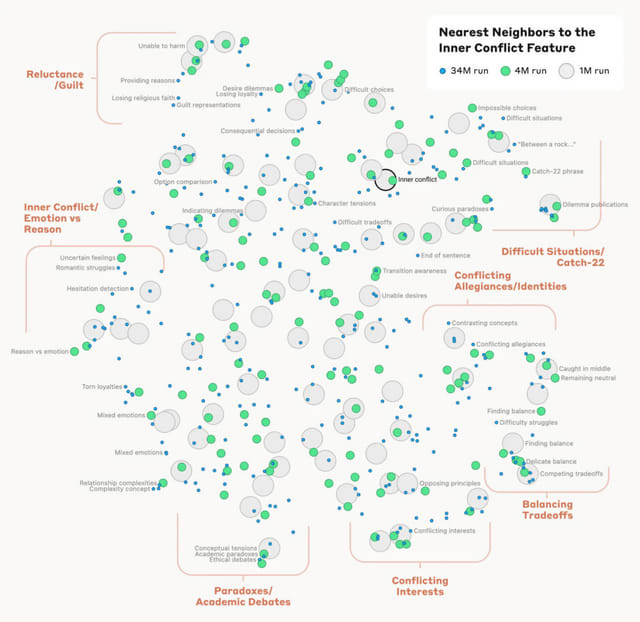
Anthropicは、同社の大規模言語モデル「Claude 3 Sonnet」の内部構造の分析結果を発表しました。内部構造を理解するために、プロンプトに反応するモデル内の活性化パターン(特徴)を抽出します。あるプロンプトを理解するために、脳内でどの部分が活性化されるかを突き止めるイメージです。
プロンプト内のワードや概念を理解するために反応した特徴を可視化し、この特徴を分析することで、モデルがどのようにワードや概念を理解しているかを明らかにします。
研究チームは、Claude 3.0 Sonnetの中間層から数百万もの特徴を特定することに成功しました。これらの特徴は、都市や人物、化学元素、科学分野、プログラミングの文法など、非常に幅広い概念に対応していました。さらに、コードにおけるバグや脆弱性、ジェンダーバイアスに関連する特徴なども見つかりました。
抽出された特徴は、多言語性やマルチモーダル性を示しました。例えば、「Golden Gate Bridge」の特徴は、英語だけでなく日本語、中国語、ギリシャ語、ベトナム語、ロシア語でも反応し、さらには画像に対しても反応を示しました。
研究者らは各特徴間の距離も測定しました。その結果、概念的に関連性の高い特徴同士が近くに位置することがわかりました。例えば「Golden Gate Bridge」の特徴の近くには、「アルカトラズ島」や「1906年のサンフランシスコ地震」などの特徴が見つかりました。
さらに研究チームは、これらの特徴を人為的に操作して、Claudeの応答がどのように変化するかを確認しました。その結果、モデルの出力を制御できることを示しました。



Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, Tom Henighan
Paper | Blog
LoRAより効率的な高いランクでファインチューニングする新しい手法「MoRA」
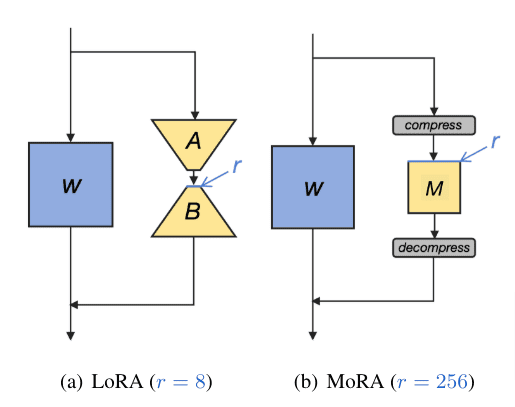
大規模言語モデル(LLM)の効率的なファインチューニング(微調整)手法として、LoRAが注目を集めています。LoRAでは、低ランク行列を用いてパラメータを更新することで、少ないパラメータ数で高い性能を実現しています。しかし、研究チームは、LoRAがLLMの新しい知識の学習や記憶能力を制限している可能性があることを指摘しています。
この問題に着目し、研究者らは「MoRA」という新しい手法を提案しました。MoRAは、LoRAと同じ数のパラメータを使いながら、より高いランクの更新を行うことができます。これは、正方行列を使うことで実現しています。さらに、MoRAで学習した重みをLoRAと同じようにLLMに組み込むことができるので、使いやすさも備えています。
様々なタスクでMoRAを評価したところ、記憶力が必要なタスクではLoRAよりも優れた性能を示し、他のタスクでもLoRAと同等の性能を達成しました。
この研究は、LLMを効率的に適応させる上で、高ランクの更新を可能にするMoRAが、LoRAの利点を受け継ぎつつ、さらに高い性能を発揮する有望な手法であることを示唆しています。
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Ting Jiang, Shaohan Huang, Shengyue Luo, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, Fuzhen Zhuang
Paper | GitHub
AI作曲「Suno」新バージョンがWAV高音質化、最長4分の曲を一発でエンディングまで完成。無修正で良曲量産可能に(CloseBox)
OpenAI、ChatGPTのMacアプリ公開。Macのカメラやスクショ、写真ライブラリにもアクセスし音声対話可能
世界13台のDNSルートサーバーのひとつに謎の同期不具合、管理者は3日間気づかず。インターネット全体が不安定になった可能性も
