by 笠原 一輝

COMPUTEX TAIPEI 2024の開幕初日に、NVIDIA CEOのジェンスン・フアン氏は報道陣関係者向けの質疑応答を行なった。この中NVIDIA版AI PCとなる「RTX AI PC」、さらにはデータセンター向けGPUのソリューションに関する質問などに関して答えた。
GeForce RTXはAI開発者にとって魅力的なプラットホーム

Q:NVIDIAのAI PC戦略に関して教えてほしい。NVIDIAはRTX AI PCの構想を発表したが……。
フアン氏:RTXはすべてのGPUに最先端のTensor Coreを備えた唯一のアーキテクチャだ。AIを学習させたい、AI推論したい、AIを開発したいという開発者にとっては「RTX」が唯一の選択肢だ。CUDAとTensor Coreがあればそれを確実に行なえる、それが「RTX」なのだ。既に世界には1億台以上のRTX GPUがあり、ノートPCにも多数採用されている。
ソフトウェアの開発者にとって重要なことは、インストールベースだ。CUDAを利用して開発していただいたソフトウェアは、CUDAと互換性がある数億台のRTX GPUで動作するし、またそのソフトウェアコードを利用してクラウドアプリケーションにすることが可能。そのようにすることで、どこでもCUDAのアプリケーションを実行できる、それが開発者にとっての勝ちだ。言うまでもなくコンピュータにとってはソフトウェアが一番重要だからだ。
これからはクラウドで実行されていたCUDAのAIアプリケーションが、PCで実行されるようになる。それによりPCにAIの機能が実装されていく、それがRTX AI PCだ。
Q:NVIDIAはNPUを開発して提供する計画があるか?
フアン氏:我々は9年前にRTXを発表し、RTXを利用してコンピュータグラフィックスの処理を行なうAI PCの取り組みを行なってきた。我々はこれをニューラルレンダリングと呼び、AIを利用した画像をレンダリングすることで表示品質を高めてきた。
また、今年(2024年)はデジタルヒューマンの仕組み「ACE」を発表し、これまではマイクロサービスのNIM(NVIDIA推論マイクロサービス)上で提供してきたが、今回は「ACE PC NIM マイクロサービス」としてノートPC上に展開できるマイクロサービス上で実行できるようにした。

ゲームにデジタルヒューマンを配置すると、ゲームのプレイを支援してもらうことも可能になる。これを我々は「Project G-Assist」と呼んでいる。これを実現するために9年間RTX AI PCに取り組んできており、既に巨大なインストールベースを持っているので、まもなくその有用性を証明できるだろう。
Q:MicrosoftのCopilot+ PCにNVIDIAのチップが対応する予定はあるか?
フアン氏:弊社はMicrosoftとNVIDIAのRTXがWindows Copilot Runtimeをサポートすると発表した。その質問はその先はどうなっているのかという質問だと思うが、本日言えることは何もない。
AMDやIntelの業界団体がつくる「UALink」への対抗は
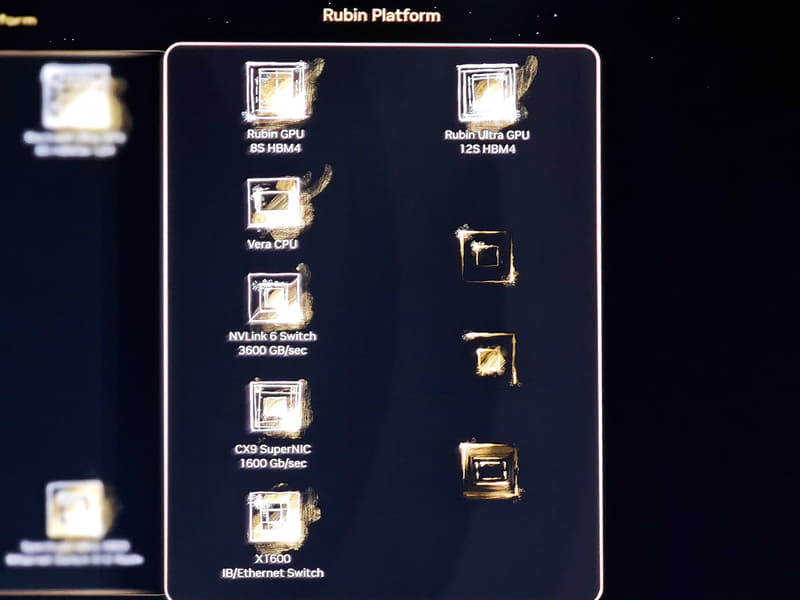
Q:基調講演では1年に1製品をリリースしていくと説明したが、NVIDIAのチップ開発について教えてほしい
フアン氏:我々の製品は早くからAIに賭けることでデザインしてきたチップだ。弊社はチップを設計し、ソフトウェアコンパイラを用意してきた。それらはこれまで誰も実現したことがないものだ。
ほかの企業では、そうしたチップ設計にかかわるようなエンジニアをレイオフしていたが、弊社は急成長しているため、多くの優秀なエンジニアを雇用できた。結局のところGPUのような巨大なチップを作るにはそれ以外に方法はないのだ。
また、弊社はGPUを作っているだけではない。それと同時にInfiniBandスイッチ、Ethernetスイッチ、NIC、NVLink Switchなどのさまざまなチップを設計して提供している。GPUを市場に届けるにはそれらのチップが同時に必要になるからだ。そして、AIスーパーコンピュータで動作するようなソフトウェアが必要になる。NVIDIAにはそれらすべてが既に揃っているのだ。だからこそ、PowerPointの資料を見せるのではなく、本当に動くシステムを皆さんにお見せできる。
Q:HBM3eに関してSK HynixとMicronがNVIDIAの認証を通り、Samsungはまだ通っていないという報道があったが、HBM3eの評価プロセスはどうなっているのか?

フアン氏:HBMは弊社にとっては非常に重要なデバイスだ。H100を構築する時にも、H200を構築する時にも、非常に高いコストをかけてそれを製品に実装した。Blackwellにもちろん採用しており、B200、B100、GB200……といった製品で採用しており、容量も重要だし、そしてスピードも重要だ。
その意味で、SK Hynixは良い仕事をしているし、MicronやSamsungもそれは同様で、その3社が我々に技術を提供してくれている。その3社が提供してくれるソリューションを正しく評価し、我々の製品に組み込もうとしている。
Q:AMDやIntelが中心となってUALink(Ultra Accelerator Link)という新しい業界団体が作られ、「NVIDIAのプロプライエタリのNVLinkは業界やユーザーのためにならない、オープンな規格が重要だ」と主張している。
歴史的に見ると、勝者は常にプロプライエタリを使い、2位以下の人がオープンというのがこの業界の常だが、NVIDIAから見てそうしたUALinkや彼らがNVIDIAのソリューションをプロプライエタリだと言っていることに関してどう思うか?
フアン氏:非常に重要なポイントだ。第一に世界はようやくNVLinkがGPUのスケールアップのために非常に重要な技術だということに気がついたということだ。
Blackwellに採用したNVLinkは5世代目に相当している。NVLinkは非常に高速で、その内部では多くのソフトウェアが動作し、同時に多くの機能を提供している。非常に複雑な仕組みによって、我々のGPUとGPUを接続しているのだ。それにより、接続されたGPUはソフトウェアから見ると1つの巨大なGPUとして動作するようになっており、これがNVIDIAの強みとなっている。
我々の競合はNVLinkが登場してから7年経って、ようやくその重要性に気がついたということだ。これから彼らはそうした業界団体で新しい規格の提案を行なっているが、それが実際に登場するまではさらに数年かかり、さらにモノになるまではさらに長い時間がかかるかもしれない。弊社がNVLinkを今の状態にするまで7年かかっているのだから。
次にNVIDIAはスケールアウトのための技術も長い時間をかけて充実させてきた。NVLinkだけでなく、NVLink Switchも充実させてきた。今ではその結果としてGB200 NVL72のように72個のGPUをラックレベルで1つの大きなGPUにスケールアップできるようにしている。そのためにこうしたバックプレーンも用意して実現できるようにしているのだ。
こうした技術を開発するために我々は7年をかけてきた。そしてようやくそれが重要な技術であったということに競合が気付いたということだ。
NVIDIAは市場シェアを取りに行く企業ではなく、新しい市場を作っていく

Q:クラウドサービス事業者(CSP)はASICのAIアクセラレータのソリューションを充実させている、それはNVIDIAにとって脅威ではないのか?
フアン氏:私がことあるごとに強調しているのは、NVIDIAはアクセラレータを提供している企業ではないということだ。NVIDIAが提供しているのはアクセラレーテッド・コンピューティングなのだ。その違いは何か?
ディープラーニングのアクセラレータは、SQLのデータ処理はできないし、同時に画像処理にも使えないし、流体力学のシミュレーションにも使えない。それに対してNVIDIAが提供しているアクセラレーテッド・コンピューティングは、もちろんディープラーニングのアクセラレータとして使うこともできるし、データ処理にも使えるし、画像処理にも使えるし、シミュレーションにも使える。汎用に使えるのがアクセラレーテッド・コンピューティングの本質だ。そのため、有用性が高く、利用率が高まれば高まるほど実行コストは低くなる。
どういうことかを電話を例に説明しよう。今皆さんが使っているスマートフォンは、昔の携帯電話に比べると非常に高価だと感じているだろう。確かにその通りだが、しかしスマートフォンは音楽プレイヤーにもなるし、カメラにもなるし、場合によってはノートPCの替わりにもなるだろう。そのように汎用性が高いため、必要対効果が高いのだ。アクセラレーテッド・コンピューティングもそれと同じで、1つの特定の用途だけでなく、汎用に使えることが価値なのだ。
だからこそ、CSPの皆さんは、AWSにせよ、Googleにせよ、Microsoftにせよ、Oracleにせよ、皆がGPUをインフラとして提供している。我々のGPUは、CUDAを活用することで、それがCSPのパブリック・クラウドにあろうが、オンプレミスにあろうが、動作するようになっている。
第二に我々の顧客はCUDAを利用しており、GPUはCSPのワークロードの演算に利用されるだけでなく、顧客自身がアプリケーションを構築してその演算に利用できるということだ。つまり顧客はCSPのソフトウェアを利用しなくても、自分のソフトウェアをCSPのGPUを利用して演算できる。そのため、顧客はCSPを選べるし、オンプレミスを選ぶこともできるということだ。どちらを経由していただいても弊社の売り上げになるのだ。
Q:生成AIへの興味の高まりとともに、データセンターの環境面への影響が言われている。それに対するNVIDIAの考えを教えてほしい。
フアン氏:3つのポイントがあると考えている。
まずにAIはアクセラレーテッド・コンピューティングを活用することが重要だ。弊社ではアクセラレーテッド・コンピューティングこそが、これからのコンピューティングの形だと考えている。汎用のプロセッサを使うと、電力は増え続け、かつ効率は上がっていかない。それに対してアクセラレーテッド・コンピューティングを使えば、コストも電力も節約できるのだ。とにかくアクセラレーテッド・コンピューティングを活用することだ。
次に生成AIで重要なのは、ラーニングだけではないということだ。推論こそが生成AIの本質だ。推論を汎用プロセッサで行なうと、電力がどんどん増えていっている、これが現在の状況であり、推論をアクセラレーテッド・コンピューティングに置きかえることで多くの電力を節約できる。
最後に、たとえば再生可能エネルギー、太陽光発電や地熱発電などをもっと生成AIのエネルギーとして活用していくことだ。たとえば、それらの発電所を人口がほとんどない場所に作り、データセンターもその近くに整備。そこでは学習を行ない、もう少しエンドユーザーに近い場所にあるエッジのデータセンターや、スマートフォンやPCなどで推論を行なう。そのように分離していくことで、エネルギーの有効活用も可能になると考えている。
Q:今回のCOMPUTEXではAMD、Intel、QualcommによるAI PCに関する話題が中心になっている。Appleもまもなくそうした機能を製品に実装するとみられているが、NVIDIAはそれらの企業と競争に勝てるのか?
フアン氏:Appleは素晴らしいデバイスを作っているし、QualcommはそのAppleと競合しているかもしれないし、AMDやIntelもAppleと競合しているだろう。しかし、我々はその世界にはいない。NVIDIAはNVIDIAの世界を作っており、その意味でそれらの企業とは競争していない。
強調したいのは、NVIDIAはマーケットシェアを取りに行く企業ではないという弊社のポリシーだ。私は常に「マーケットメーカー(筆者注:市場を創造するという意味)であれ」と社員に言っている。
我々のGeForceはゲーム用に設計された最初のGPUだ。それによりNVIDIAは3Dゲーム市場の発展に大きく貢献した。そしてこれまでお話ししてきたアクセラレーテッド・コンピューティングの創造、自動運転自動車、ロボット、デジタルツインなどの取り組みを創造し、現在もその取り組みを行なっている。我々が、市場ができ始めた初日からそこにいて、カテゴリ全体を創造してきたことに異論を唱える人はいないと思う。
これが弊社の文化であり、個性は未来を発明することだ。弊社は夢想家であり発明家なのだ。そしてそれらを構築したあと、エコシステムを解放し、それを利用して未来をつくれるようにしてきた。NVIDIAは単にチップを提供する企業ではなく、そうした未来を作るためのAIスーパーコンピューターを提供する企業だ。
今はCSPがAIアクセラレータを作っているので、CSPはNVIDIAの競争相手だと言う人もいる。彼らは彼らで顧客が必要としているものを提供されているのだと思うが、NVIDIAはアクセラレータではなく、ディープラーニング、生成AI、データベース処理、気象シミュレーションなどあらゆる領域のアプリケーションを処理するのに必要な汎用的なアクセラレーテッド・コンピューティング・プラットホームを提供しており、それを提供する(競合というのはいない)唯一の企業なのだ。
