一般公開されていないOpenAIの「Sora」や、特定の人にしか使えない中国発の「Kling」の動画生成精度を尻目に、「Luma Dream Machine」という動画生成AIが登場しました。精度が高く、今すぐ誰でも無料で使えるということで話題になっています。
YouTube広告を16倍速であっという間に終わらせるChrome拡張が公開、広告ブロック警告を回避
また、AppleがWWDC 2024において、自社開発のAIシステム「Apple Intelligence」を発表しました。
さらに、Stability AIがテキストから画像を生成する新モデル「Stable Diffusion 3 Medium」をリリースしました。
さて、第51回の生成AIウィークリーでは、この1週間の興味深い生成AIに関する研究論文をピックアップし、解説します。特に注目したいのは、大規模言語モデル(LLM)の開発において、常識とされている行列乗算を排除するという「MatMul-Free LM」です。この研究は、GitHubにおいて2000件(執筆現在)のStarを獲得しており、注目されています。
生成AI論文ピックアップ
1枚の画像に写る人物キャラクターに楽曲を歌わせるアニメーションを生成できるAIモデル「Hallo」
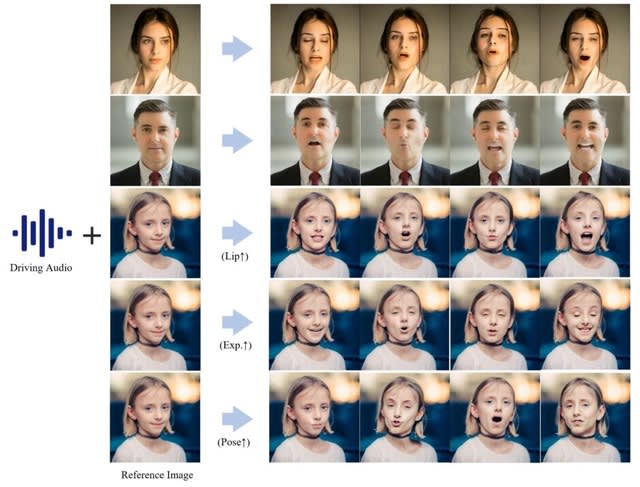
「Hallo」は、アニメーションを生成したいキャラクターの静止画像と、キャラクターの動きを駆動する音声データを入力し、音声に応じたリアルで表情豊かなポートレート画像アニメーションを生成する技術です。音声入力に駆動される口の動き、顔の表情、および頭の動きの同期と調整を行い、視覚的に魅力的で時間的に一貫性のある高品質のアニメーションを生成します。
従来の手法では、顔のランドマークや3Dパラメトリックモデル(3DMM、FLAME、HeadNeRFなど)を中間表現として利用していました。また、潜在空間での表現学習の分離を行う手法もありましたが、静的および動的な顔の属性を包括的に捉えることが難しいという課題がありました。これらの手法では、中間表現の精度と表現力に限界があり、自然で多様な表現を実現するのは困難でした。
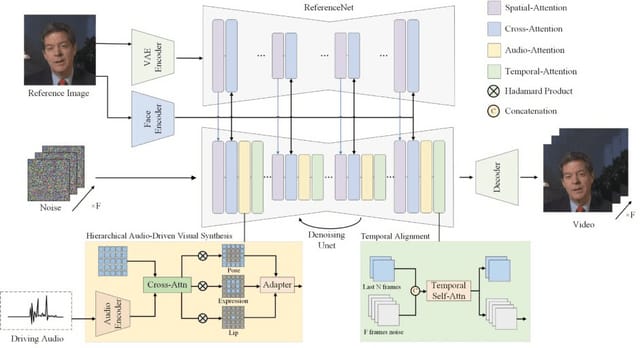
Halloでは、中間表現を必要とせずに、エンドツーエンドの拡散モデルを採用しています。具体的には、階層的なオーディオ駆動視覚合成モジュールを導入し、Cross-Attentionメカニズムを用いて、音声と視覚的特徴(唇、表情、ポーズ)の対応関係を学習しています。さらに、UNet-based denoiser、時間的アライメント技術、ReferenceNetを統合したネットワークアーキテクチャを提案しています。これにより、正確な唇の同期、豊かな表情と頭の動きを実現しています。
また、Halloではリップシンク、表情、ポーズの多様性を適応的に制御できるため、それぞれの動きのバランスを目的に応じて調整することができます。例えば、リップシンクの強度を高くすると大袈裟に口を大きく開けるようになるという具合です。
研究チームは、定量的および定性的な評価により、画像とビデオの品質、唇の同期精度、モーションの多様性において、Halloが従来手法と比較して優れた性能を示すことを確認しました。
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Luc Van Gool, Yao Yao, Siyu Zhu
Project | Paper | GitHub
“行列乗算なし”で大規模言語モデルを開発する手法「MatMul-Free LM」
近年、大規模言語モデル(LLM)の性能が飛躍的に向上していますが、その計算コストの大部分を占めているのが行列乗算(MatMul)です。LLMの規模が大きくなるほど、この問題は顕著になります。
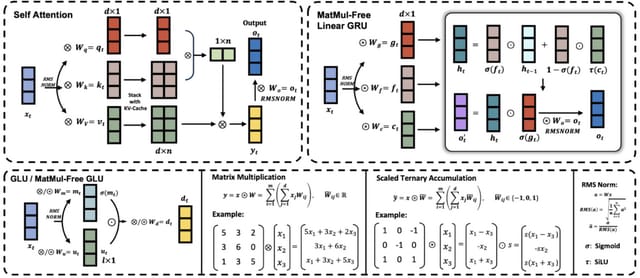
そこで今回、LLMから行列乗算を完全に排除しつつ、大規模で高い性能を維持する手法を提案します。通常、ニューラルネットワークの密な層では、入力と重みの行列を掛け合わせて計算を行います。しかし、本モデルでは、重みを-1、0、+1の3つの値に限定することで、掛け算を加算と減算に置き換えました。自己注意機構では、通常、行列同士の掛け算を行いますが、本モデルでは要素ごとのアダマール積を使用します。
研究チームは、370M、1.3B、2.7Bのパラメータを持つ3つのモデルサイズで、MatMul-free LMと従来のTransformerモデルの性能を比較しました。実験の結果、提案手法を用いたMatMulフリーモデルは、行列乗算を使用する最先端のTransformerと同等の性能を達成しました。さらに、モデルのサイズが大きくなるほど、MatMulフリーモデルとTransformerの性能差は縮まることがわかりました。
GPUに最適化された実装により、MatMul-freeモデルのトレーニング時にメモリ使用量を最大61%削減し、推論時のメモリ消費を10倍以上削減しました。さらに、FPGAを用いたカスタムハードウェアを構築し、低消費電力で高速処理できることを示しました。

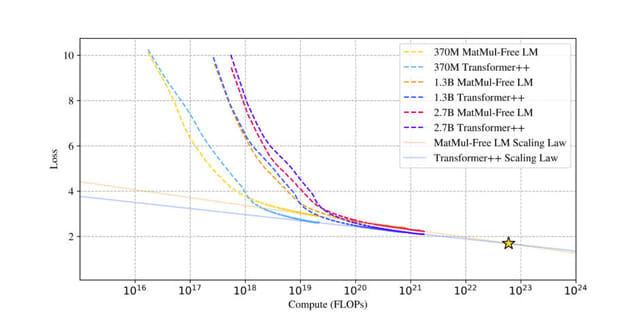
Scalable MatMul-free Language Modeling
Rui-Jie Zhu, Yu Zhang, Ethan Sifferman, Tyler Sheaves, Yiqiao Wang, Dustin Richmond, Peng Zhou, Jason K. Eshraghian
Paper | GitHub
オートリグレッシブモデルによる高品質な画像生成AI「LlamaGen」
大規模言語モデル(LLM)は、大量のテキストデータを学習することで、人間のような自然な文章生成や対話を可能にします。この成功に触発され、画像生成の分野でもLLMと同じアーキテクチャを用いたオートリグレッシブモデルの研究が活発になっています。
オートリグレッシブモデルとは、過去の出力を入力として次の出力を予測するモデルです。画像生成の文脈では、画像を一連のトークンに分解し、それらのトークンを一つずつ順番に予測していくことで、最終的に完全な画像を生成します。
今回、このオートリグレッシブモデルを用いた画像生成モデルが「LlamaGen」です。LLMと同じアーキテクチャを採用しながら、視覚的な信号に対する特化したバイアスを削減することで、高品質かつスケーラブルな画像生成を実現しました。
LlamaGenの特徴は、高性能な画像トークナイザー、スケーラブルな画像生成モデル、そして高品質の学習データにあります。画像トークナイザーは、ImageNetベンチマークにおいて高い再構成品質を達成しました。
画像生成モデルは、1.1億から31億のパラメータを持つモデルを開発し、ImageNetベンチマークで他の拡散モデル(例:LDM、 DiT)を上回る性能を示しました。LAION-COCOと高品質の画像データセットを用いた2段階学習により、テキスト条件付き画像生成モデルも高い視覚的品質とテキストとの整合性を実現しています。

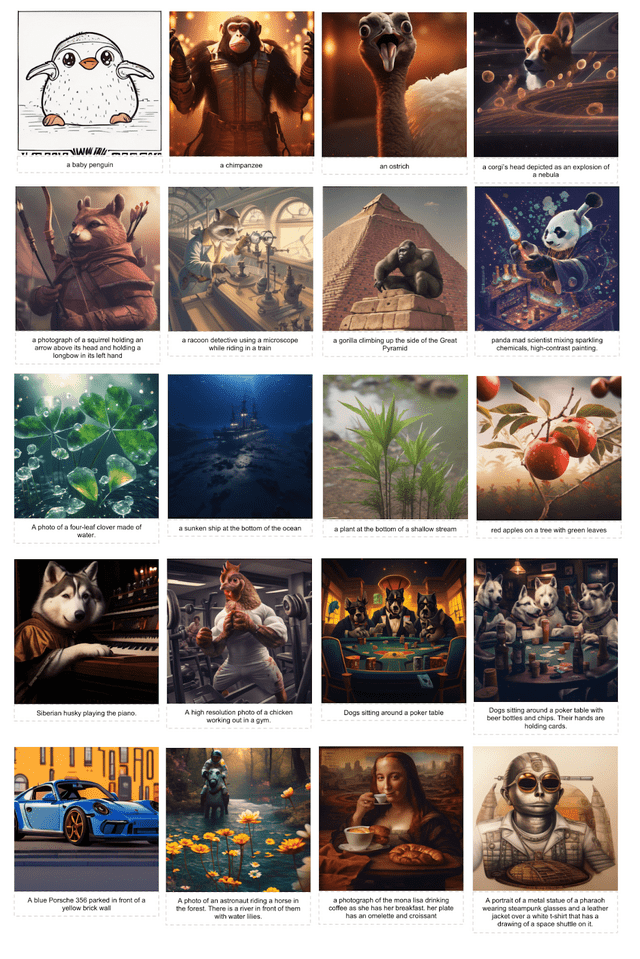
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, Zehuan Yuan
Project | Paper | GitHub | Demo
動画を高精度に理解するモデル「VideoLLaMA 2」をアリババグループが開発
「VideoLLaMA 2」は、ビデオ理解とオーディオ理解の能力を高めたビデオ大規模言語モデル「Video-LLMs」の新しいバージョンです。
動画に関する質問応答、動画のキャプション生成、音声のみの質問応答など、幅広い用途に応用可能です。また、長い動画の理解、ビデオエージェント、自動運転、モーション理解、ロボットの操作などにも活用できる可能性を持っています。
このモデルは、前身のVideoLLaMAをベースに、空間的・時間的モデリングを強化する「Spatial-Temporal Convolution」(STC)コネクターと、音声理解を統合するAudio Branchを組み込むことで発展しました。
VideoLLaMA 2は、複数の動画に関する質問応答(MC-VQA)、オープンエンドの動画に関する質問応答(OE-VQA)、動画のキャプション生成(VC)などのタスクで、オープンソースモデルの中でトップクラスの性能を示し、いくつかのベンチマークでは市販モデルに匹敵する結果を出しています。また、音声のみの質問応答(AQA)や音声付き動画の質問応答(AQA & OE-AVQA)のベンチマークでも、既存のモデルを上回る改善を示しました。
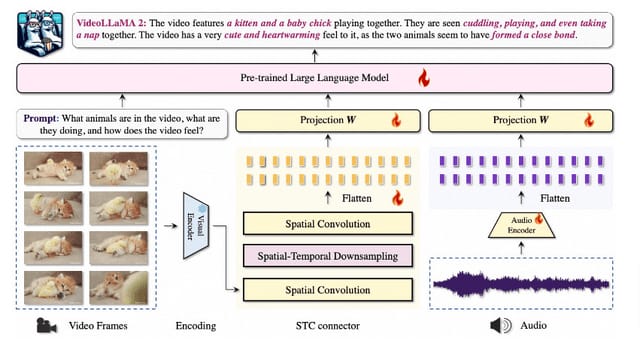

VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, Lidong Bing
Paper | GitHub | Demo
画像1枚から複雑な深度情報を抽出するモデル「Depth Anything V2」をTikTokなどが開発
1枚の画像から深度情報を推定するための新しいモデル「Depth Anything V2」を発表しました。前バージョンであるDepth Anything V1の後継モデルです。
V2では、V1の長所を継承しつつ、いくつかの重要な改良が加えられています。まず、ラベル付き実画像をすべて高品質な合成画像に置き換えることで、より詳細で正確な深度予測が可能になりました。次に、教師モデルを拡張し、大規模なラベル付き実画像を用いて学生モデルをトレーニングすることで、実画像に対する汎化性能が大幅に向上しました。
また、V2では25Mから1.3Bまでの様々なパラメータ数のモデルが提供されるようになり、幅広いアプリケーションでの利用が可能になりました。これにより、ユーザーは自分のタスクに適したモデルサイズを選ぶことができます。
V1では苦手とされていた透明物体やミラー面などの困難なシーンにおいても、V2は大幅に推定精度を向上させています。これは、合成画像を使ったトレーニングによって、これらの特殊なシーンに対する深度推定の能力が向上したためです。
さらに、研究チームは新たな評価用データセット「DA-2K」を構築しました。このデータセットは、高解像度の画像と正確な深度ラベルを持ち、多様なシーンをカバーしています。DA-2Kにおいても、V2は優れた性能を示しており、最も軽量なモデルでさえ他の大規模モデルを上回る結果を達成しています。
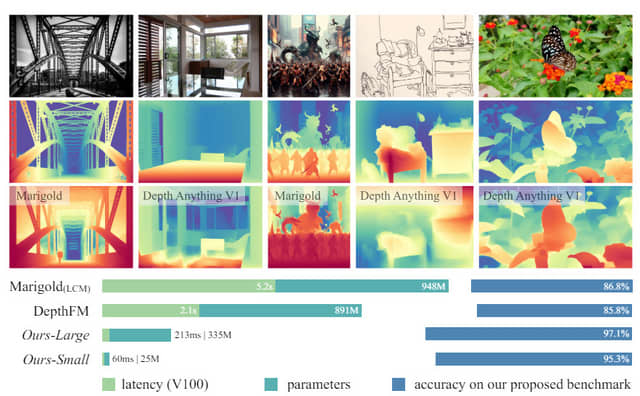

Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
Project | Paper
もうSoraは不要なのか。動画生成AIの新基準、Luma AI「Dream Machine」をサブスクしてわかった「ハリー・ポッターに出てくるような魔法」の使いこなし術(CloseBox)
今そこにあるSora、現時点最高クラスの誰でも使える動画生成AI「Luma Dream Machine」が人気すぎて数時間の待ち行列(CloseBox)

