東京商工リサーチ(TSR)は、一橋大学、有限責任あずさ監査法人と共同で、機械学習の手法を用いた非上場企業の会計不正のリスクをスコアリングするモデルの研究成果をまとめ、一橋大学ワーキングペーパー「機械学習手法を用いた不正会計予測:非上場企業データを用いた検討」 として、6月22日に公表しました。
本稿では、ワーキングペーパーの主要部分を解説します。
「企業間取引の円滑な実施」は突き詰めれば、双方の信認をベースに誠実に取引が行われるということに尽きます。それが大きく揺らぐケースの一つとして、上場企業であれば「開示情報の誤り」は、取引金融機関や、実物取引における販売先、仕入先、そして市場からの信認を失いかねない重要なインシデントであります。また、上場・非上場に限らず、企業の開示情報の誤りが企業による何らかの意図のもとで行われた場合は、会計情報に関する不正行為(不正会計)とみなされ、当局からのペナルティが課され、信用の失墜を招き、多くのステークホルダーに多大な影響を与え倒産する場合もあります。
このように、企業を取り巻く広範囲に多大なる負の影響を及ぼす不正会計に対し、これまでその重要性から多くの既存研究で、不正会計の発生パターンに関する理論的な検討が進められ、「不正会計の検知」「予測」を目的とした実証モデルの構築が議論されてきましたが、一方、より実務的な観点からは以下の課題が認識されています。
(1)不正会計の予測モデルの構築にこれまでの研究では利用されていない膨大な情報が存在しており、これらの情報の利用によるモデル精度向上の可能性
(2)大規模なデータと、その処理が得意な機械学習の手法を用いた予測モデル構築が効果的である一方で、データ収集に係るコストの観点から、可能な限り少ない情報をもとにして高精度な予測モデルの構築が求められる
これは一見矛盾するようにも見えますが、多数の財務指標、金融機関や取引関係、株主、立地など、企業に関する数多の情報が該当し、これらを予測モデルの構築に用いた方が、より精度高く不正会計が予測できるのではないかという直感的な期待がある一方で、それら膨大な情報の中でも、コストメリットの観点からモデル構築に必要な情報の取捨選択を行うことで、データ収集を「低コスト」で達成するという実務的なニーズに合致します。本研究はこの2つの課題を念頭に分析をすすめていきました。(脚注1)
分析は、TSRが保有する非上場企業を含む2014年から2017年の期間における詳細な財務情報を伴う各年30万社程のデータに対して、企業のネガティブイベントに関するテキスト情報から構築した不正会計イベントの発生を示すフラグを該当の企業に付与した上で、不正会計の予測変数(予測するために投入する情報)として実証会計分野で一般的に用いられている変数のほか、企業属性、実物及び金融面における取引関係情報、同業他社情報、周辺立地情報、株主関係情報などを変数として用いた予測モデルを構築しました。

構築した予測モデルに対し、モデル構築に用いなかった企業群にてAUC指標に基づく精度評価を実施したところ、0.8を上回る予測精度が実現されました 。(脚注2)
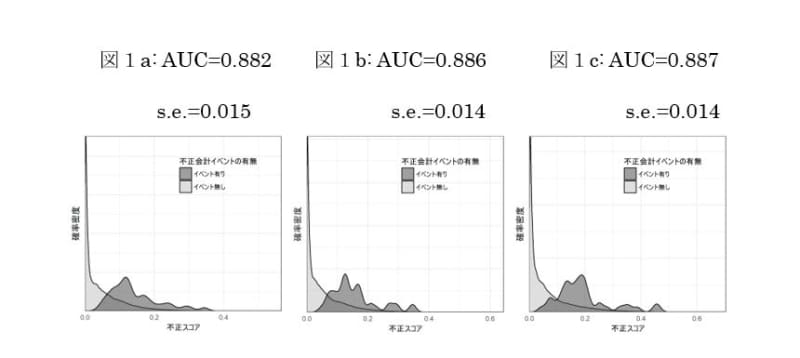
図1aは非上場企業(上場企業子会社を除く)を対象とする企業群に対して「信用評点」及び「企業自身の情報」のみを用いて構築したモデルの予測精度について、モデル構築に用いなかった企業群での不正会計イベントが有ったサンプルと、なかったサンプルのスコア分布をAUCと共に示したものです。同様に図1bは「信用評点」「企業自身の情報」「上場ステータス」のみを、図1cは「信用評点」「企業自身の情報」「上場ステータス」「親子関係情報」のみを用いた場合の結果をAUCと共に示しています。何れのケースも0.8を超えるAUCが達成されました。
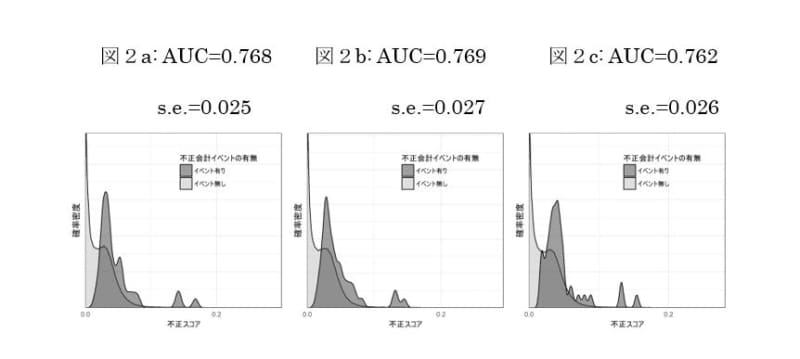
第二に、図2a~cは、図1の三枚に対応するモデルへ、「財務指標」「地理・業種情報」「銀行関連情報」「取引関係情報」「実証会計分野の情報」を追加したときのスコア分布をAUCと併せて示したものです。何れのケースにおいても0.8弱のAUCが達成されており実務的には相応の予測精度が得られていると言えます。しかし、予測変数を拡充したにもかかわらず図1記載の各ケースに比して予測精度が低下しているという結果は、極めて大規模な情報がもたらすベネフィットが過剰適合などのコストによって相殺されていること、すなわち余分な情報が投入されてしまっていることを示唆しています。
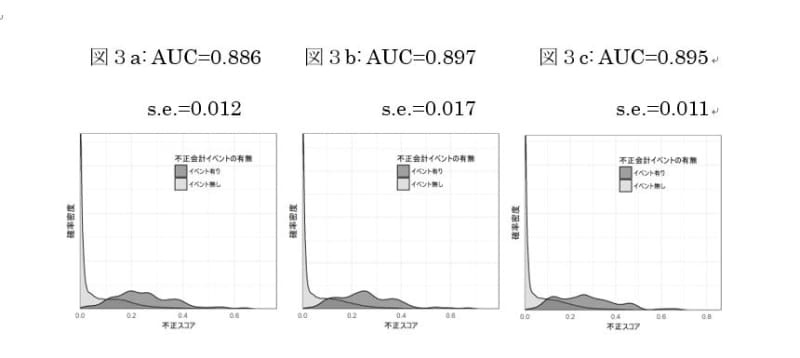
最後に、図3の3枚のパネルは図1の3枚のパネルにおける予測変数の選択パターンを維持したうえで、分析対象企業へ上場企業と上場企業子会社を含めた上で再度予測モデルの構築を行い、モデル構築に用いなかった企業群での予測精度を確認したものです。比較的コンパクトな予測変数群で十分な予測精度が実現されているという上記の結果が、予測対象を拡充した場合でも引き続き確認されています。
これらの結果は、機械学習手法を用いた不正会計予測モデルの有効性が非上場企業でも確認されることを意味しています。このように、不正会計フラグと企業レベルの複数年のデータを利用することができれば、実務的に有効な取り組みが可能となるということがわかりましたが、幾つかの留意点も存在します。
第一に、本研究では明示的に示していませんが、上場企業「のみ」を対象とした不正会計の予測精度という点について、この度構築したモデルは、共同研究者のあずさ監査法人と一橋大学が膨大な財務指標を用いて予測モデルを構築した研究の結果(宇宿ほか (2019))に必ずしも及んでいません。(脚注3)この点に関連して、上場企業のみを対象として本研究で用いたフレームワークの下で上場企業向けの不正会計予測モデルを構築した場合には、予測変数へ財務指標を含めることで予測精度が大幅に改善している結果が得られています。これらの結果は、上場企業を対象とした不正会計予測において、多くの種類の財務指標が重要な役割を果たしていたことを示唆しています。
第二に、予測モデルの構築に際して常に生じる問題として、モデルの構造変化(concept drift)の問題が挙げられ、不正の手口も変遷があることからこの問題がより深刻となる可能性があります。この点に関して、本研究で用いた機械学習手法は迅速なモデルの改訂が可能であるという点で、裁量的な判断を必要とする局面を多く含む伝統的なパラメトリックモデルに比して優位性があると考えられますが、何れにしてもモデルの陳腐化による予測精度の低下が恒常的な問題として存在していることは認識すべきであるといえます。
- 1)TSRが保有する企業データを用いた企業レベルのダイナミクス(例:休廃業、解散、被合併、売上成長)予測モデルを構築した事例として、一橋大学とTSRによる共同研究成果である特許「企業情報処理装置、企業のイベント予測方法及び予測プログラム」(特許番号:第6611068号、特許取得日:令和1年11月8日)が挙げられます。本研究で構築した不正会計予測モデルはこの技術に基づいて実施されました。
- 2)AUC指標は、不正会計イベントの発生があった企業群と、発生が無かった企業群それぞれからランダムに選択された2つのサンプルに対し、正しく不正会計リスクの高低のスコア(ランク)付けがされる確率を示す指標
- 3)宇宿 哲平、近藤 聡、白木 研吾、菅 美希、宮川 大介、「機械学習手法を用いた不正会計の検知と予測」、2019年7月、独立行政法人経済産業研究所、ディスカッションペーパー、2019年度、No.19-J-039、2021年8月16日検索、
URL: https://www.rieti.go.jp/jp/publications/dp/19j039.pdf
Number:FS-2021-J-001
Title:機械学習手法を用いた不正会計予測:非上場企業データを用いた検討
Author:あずさ監査法人(宇宿哲平、近藤聡、白木研吾)、一橋大学(宮川大介)、TSR(柳岡優希)
全文は、https://www.fs.hub.hit-u.ac.jp/staff-research/workingpaper/ でご覧いただけます。
(東京商工リサーチ発行「TSR情報全国版」2021年8月30日号掲載「特別レポート」を再編集)

