
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第49回目は、生成AI最新論文の概要5つを紹介します。
YouTube広告を16倍速であっという間に終わらせるChrome拡張が公開、広告ブロック警告を回避
生成AI論文ピックアップ
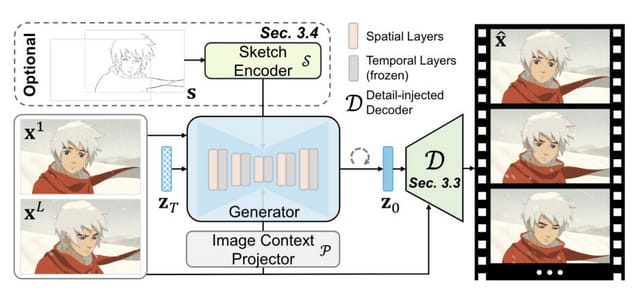
アニメの“中割り”を生成してアニメーションに仕上げる「ToonCrafter」
アニメーション制作は、フレームごとに手描きで行われるため、非常に手間がかかる作業です。そのため、フレームとフレームの間の映像(中割り)を自動生成する補完技術が重要となります。しかし、アニメーション特有の課題により、実写映像の補完技術をそのまま適用しても十分な品質が得られません。
研究チームは、実写映像の動きの事前知識をアニメーション補間に活用する新しい生成的枠組みを探求しました。この技術は「ToonCrafter」と呼ばれ、実写映像から学習した豊富な動きの事前知識を利用して、アニメーション補間のための効果的な生成的枠組みを構築します。
具体的には、ToonCrafterは以下の3つの主要な技術から成ります。まず、実写映像の動きの事前知識をアニメーション領域に適応させる学習戦略を採用しています。次に、劣化を抑え、詳細な絵を保持するためのデコーダーを使用しています。最後に、ユーザーが動きを調整できるインタラクティブなスケッチエンコーダーを備えています。
ユーザーは、補間したい2枚の連続した絵(最初のフレームと最後のフレーム)を入力します。ToonCrafterは、途中の絵がない場合でも、その間のアニメーションをなめらかに生成することができます。
さらに、中割りしたい動きのガイドとなる簡単な線画を追加で入力することで、動きを調整できます。また、線画映像に色付きの絵を入力してアニメーションに色を付けることも可能であり、逆に、1枚の色付き絵を基に線画映像の動きを組み合わせたアニメーション生成もできます。
評価実験の結果、ToonCrafterは数値評価およびユーザー評価において既存の手法よりも優れた性能を示しました。特に、難しい動きや遮蔽のあるシーンでも高品質な補間を実現したことが確認されました。


ToonCrafter: Generative Cartoon Interpolation
Jinbo Xing, Hanyuan Liu, Menghan Xia, Yong Zhang, Xintao Wang, Ying Shan, Tien-Tsin Won
Project | Paper | GitHub | Demo
1枚の画像とモーションデータからダンス動画を生成するAIモデル「MusePose」
MusePoseは、1枚の画像とポーズシーケンス(骨格動画)を入力に、ダンスビデオを生成するAIフレームワークです。モーションデータの動きに合わせて、画像内のキャラクターを踊らせることができます。
過去にも、AnimateAnyoneなど、さまざまな類似技術が登場していますが、今回のモデルはより滑らかな動きで一貫性を保ったアニメーションを生成します。評価実験の結果においても、同じ分野の現在のほぼすべてのオープンソースモデルを上回っているといいます。
執筆現在、プロジェクトページや技術論文は近日公開としています。
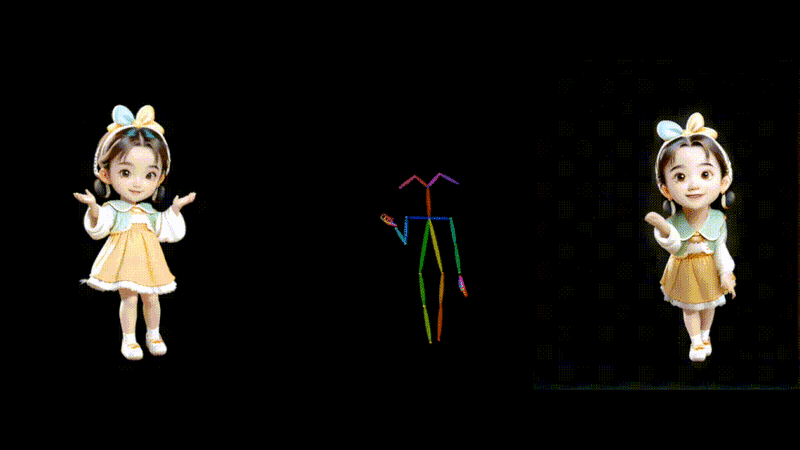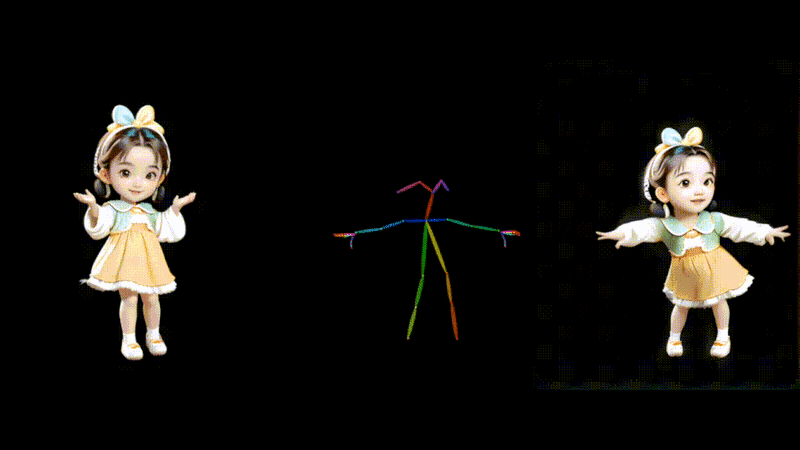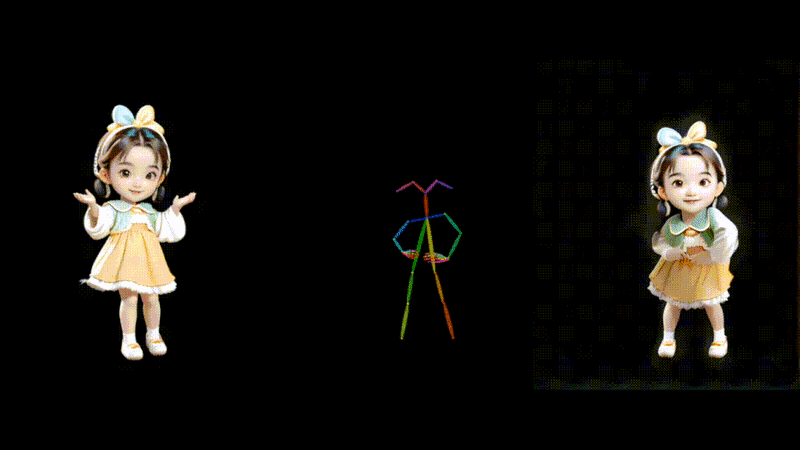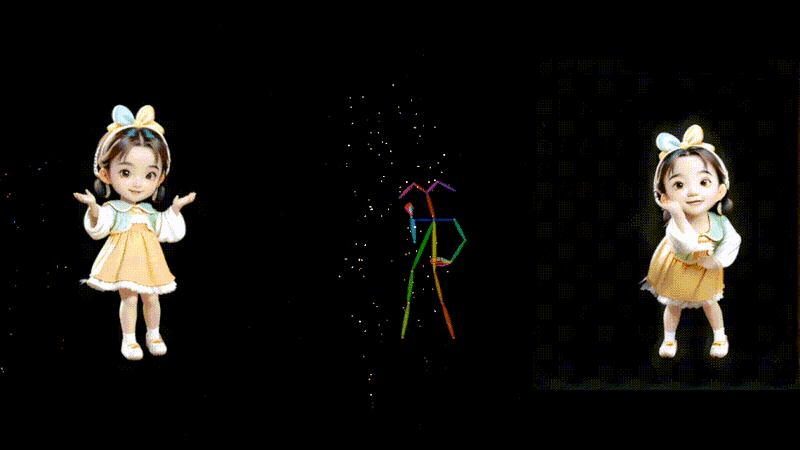
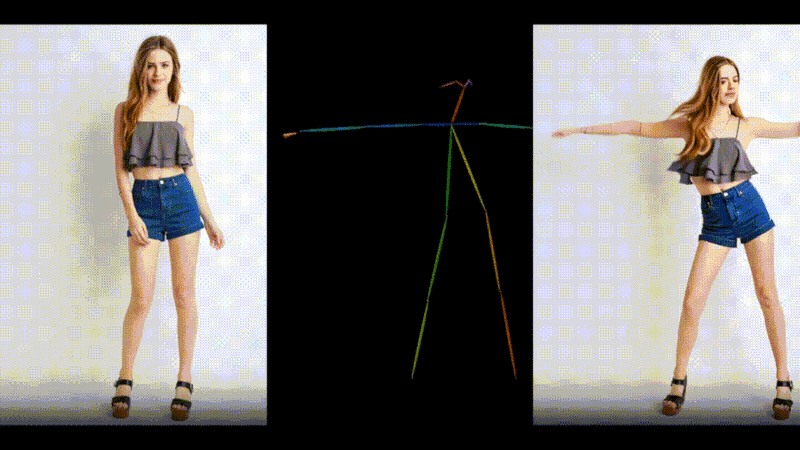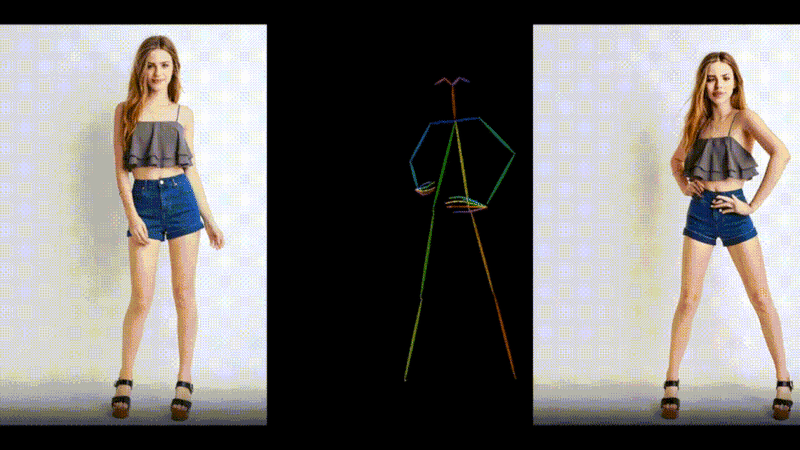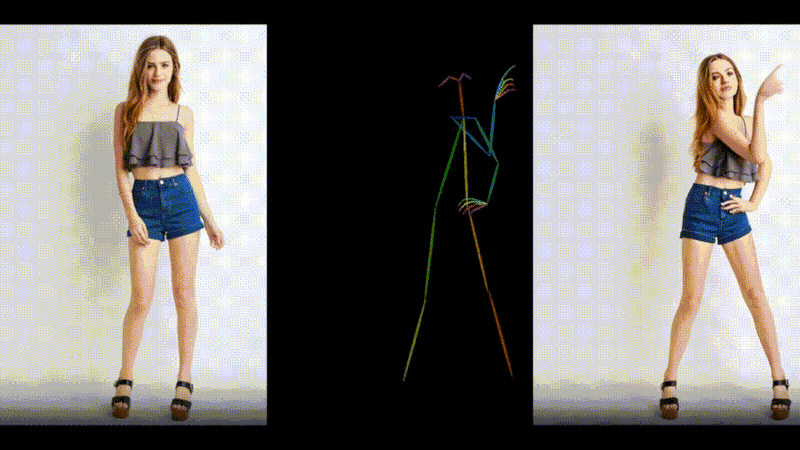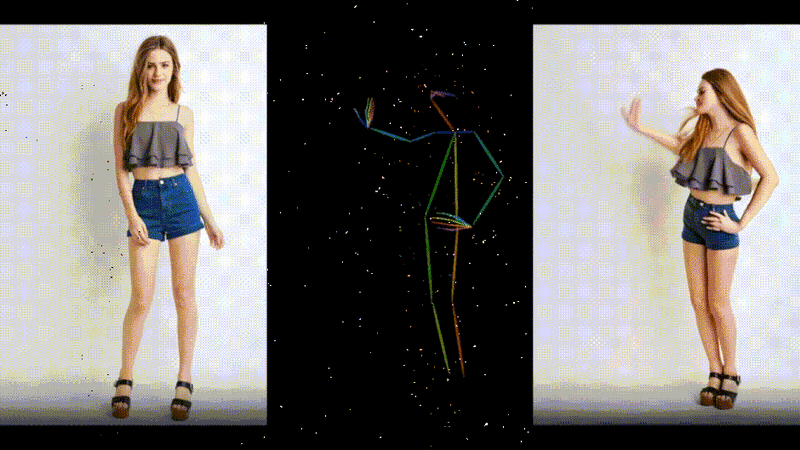
MusePose: a Pose-Driven Image-to-Video Framework for Virtual Human Generation
Zhengyan Tong, Chao Li, Zhaokang Chen, Bin Wu, Wenjiang Zhou
GitHub | Hugging Face
リアルタイムでストリーミング動画を変換するAIモデル「StreamV2V」
「StreamV2V」は、ユーザーが指定した内容に従ってリアルタイムでストリーミング動画を変換できる技術です。従来の動画変換技術は一度に少しの動画しか処理できませんでしたが、StreamV2Vはストリーミング方式でフレームを逐次処理するため、長時間の動画でもリアルタイムに対応できます。
StreamV2Vは、過去のフレームの情報を保存しておき、新しいフレームを処理するときにその情報を使って似ている部分を見つけ出します。そして、似ている過去の情報を現在のフレームに反映させることで、動画全体の一貫性を保ちます。古い情報と新しい情報をうまく混ぜ合わせて更新されるので、情報量が多くてもデータ量は少なく保てます。
StreamV2Vは適応性と効率性に優れており、ファインチューニングなしで画像拡散モデルとシームレスに統合できます。また、1つのA100 GPUで20FPSで動作可能であり、FlowVid、CoDeF、Rerender、TokenFlowと比較して、それぞれ15倍、46倍、108倍、158倍高速です。定量的な指標とユーザースタディにより、StreamV2Vの時間的一貫性を維持する優れた能力が確認されました。
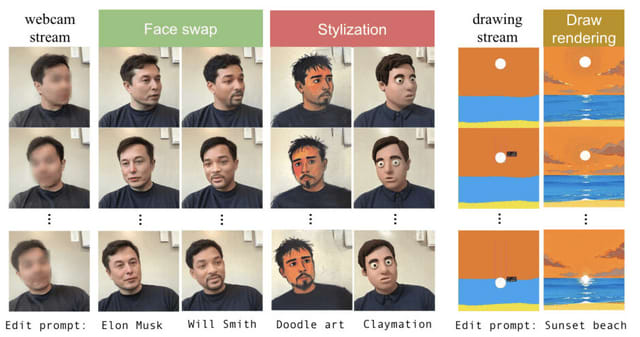
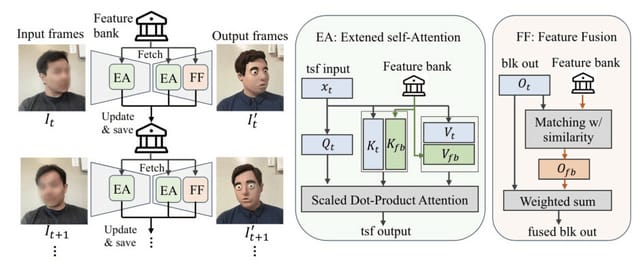
Looking Backward: Streaming Video-to-Video Translation with Feature Banks
Feng Liang, Akio Kodaira, Chenfeng Xu, Masayoshi Tomizuka, Kurt Keutzer, Diana Marculescu
Project | Paper | GitHub | Demo
写真1枚から人物やキャラクターの話す動画を生成するモデル「V-Express」
近年、1枚の写真からポートレートビデオを生成する技術が注目されています。一般的な方法は、生成モデルを使って、テキストや音声、ポーズなどの条件に合わせてビデオを生成することです。
しかし、条件(テキスト、オーディオ、参照画像、ポーズ、深度マップなど)の強さにはバラつきがあり、弱い条件は強い条件に邪魔されて上手く機能しないことが多いです。弱い条件は強い条件の干渉を受けて効果を発揮しにくく、これらの条件のバランスを取ることが課題となります。
研究において、オーディオが特に弱く、ポーズや元の画像などの強い条件に負けてしまうことを特定しました。これに対処するために、研究者らは「V-Express」という、段階的な操作を通じて異なる条件のバランスを取る方法を提案します。
この方法は、弱い条件による効果的な制御を段階的に可能にし、ポーズ、入力画像、および音声を同時に考慮した生成能力を達成します。実験結果は、この方法が音声によって制御されたポートレートビデオを効果的に生成できることを示しています。
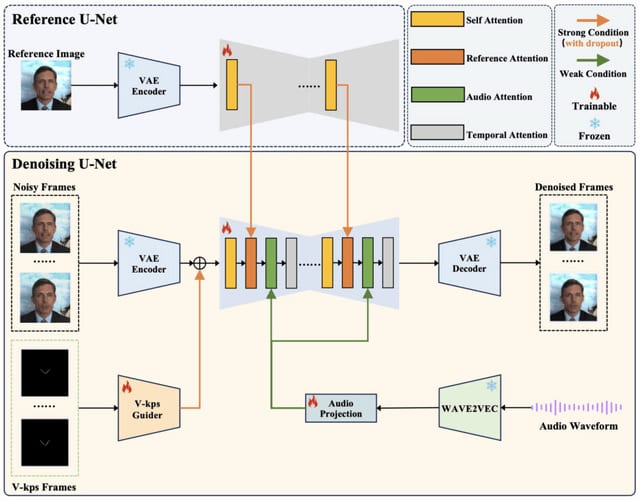
V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation.
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen,Zhiwei Jiang, Qing Gu1, Xiao Han, Wei Yang
Project | GitHub | Hugging Face
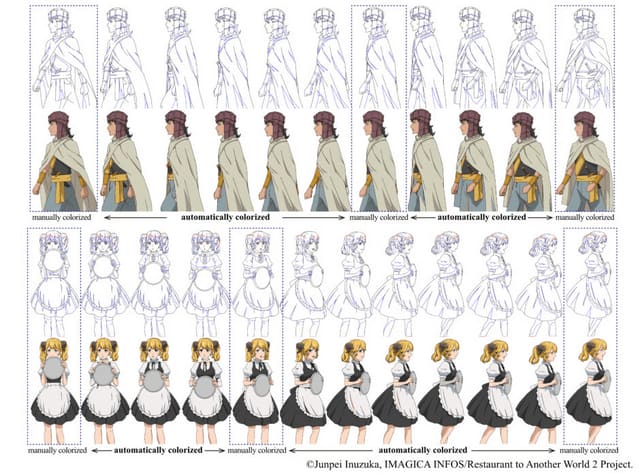
人の手で塗った数枚の線画から、残りのアニメーションを自動彩色できるAIモデル
アニメの制作では、キャラクターなどの線画に色を塗る作業があります。これは手作業で行われることが多く、非常に時間がかかります。
従来の自動彩色手法には、機械学習を用いたカラー予測、ユーザー指定のカラーヒントに基づくカラー伝播などがありましたが、これらの手法は実用上の問題から制作現場での導入が限定的でした。
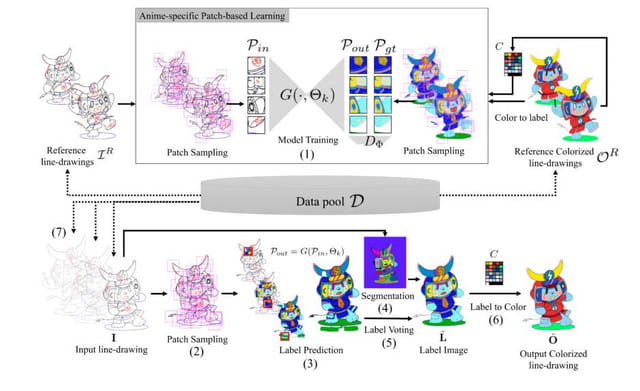
この研究では、これらの課題を解決すべく、アニメ様式の彩色に特化した新しいパッチベース学習法を提案しています。主な特徴は、アニメ線画の特性を考慮した効率的なパッチサンプリング手法と位置埋め込みを用いることで学習の効率と精度を向上させること、少数の手作業による彩色済み線画を用いて、ゼロショット学習あるいは事前学習済みモデルのファインチューニングにより彩色モデルを構築できることです。
ユーザーは対象となるアニメーションのシーケンスから少数の線画を選び、手動で彩色し、カラーパレットを設定します。そして、手動で彩色した線画と対応するラベルマップをシステムに提供します。
提案手法の有効性は、テレビアニメシリーズから抽出されたデータセットで評価されました。その結果、提案手法が先行研究の手法と比較して優れた性能を示すことが確認されました。
Continual Few-shot Patch-based Learning for Anime-style Colorization
Akinobu Maejima, Seitaro Shinagawa, Hiroyuki Kubo, Takuya Funatomi, Tatsuo Yotsukura, Satoshi Nakamura, Yasuhiro Mukaigawa
Project | Paper
AI作曲「Suno」新バージョンがWAV高音質化、最長4分の曲を一発でエンディングまで完成。無修正で良曲量産可能に(CloseBox)
