
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第50回目は、生成AI最新技術の概要5つを紹介します。
OpenAI、ChatGPTのMacアプリ公開。Macのカメラやスクショ、写真ライブラリにもアクセスし音声対話可能
生成AI論文ピックアップ
Soraに匹敵する動画生成AI「KLING」登場。中国のショート動画アプリ開発チーム「快手」が手がける
中国のショート動画共有アプリを開発する「快手」(Kuaishou)は、ビデオ生成モデル「可灵大模型」(KLING)を発表しました。論文などの詳細は公開されていませんが、Webで専用ページが公開されています。
そこにはサンプル動画が多数掲載されており、OpenAIの動画生成AI「Sora」級に高品質だと話題になっています。
KLINGは、テキストから最大2分間の動画を30fpsのフルHDで生成できるAIモデルです。同社が自社開発する3D VAEに基づいています。
また、1枚の画像内に写る人物をポーズシーケンス(骨格動画)に基づいて踊らせるアニメーションのデモ動画も掲載されており、テキストから動画を生成するだけでなく、モーションデータの動きに合わせて画像内のキャラクターを動かす能力も備わっています。
Klingを試すには、同社が提供するアプリ「快影」をインストールすることで、アプリ内で使えます。ただし、使用には中国の電話番号が必要です。


KLING
快手(Kuaishou)
Project | Paper | GitHub | Demo | Blog
アリババグルーブが開発するオープンソースな大規模言語モデルの新バージョン「Qwen 2」登場
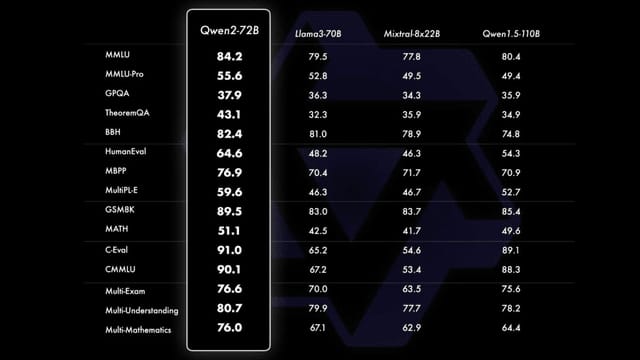
Alibaba Cloudは最新の言語モデルであるQwen 2シリーズを発表しました。Qwen 2はQwen 1.5から進化したモデルで、5つのサイズ(0.5B、1.5B、7B、57B-A14B、72B)のモデルが利用可能です。
英語と中国語に加えて27の言語での学習データを活用 ・自然言語理解、知識獲得、コーディング、数学、多言語対応などのベンチマークで高いパフォーマンスを示しています。コーディングと数学の能力が大幅に向上し、最大128Kトークンまでの長文コンテキストに対応(7Bと72Bモデル)します。
大規模モデルのQwen 2-72Bは、LLama-3-70Bなど他のSOTAモデルと比較して、さまざまなタスクで優れたパフォーマンスを示しています。また指示ファインチューニング後のQwen 2-72B-Instructは、16のベンチマークタスクで総合的に高いスコアを達成しています。
小規模モデルのQwen 2-7B-Instructも、同等かそれ以上のサイズの他モデルと比べて優位性があり、特にコーディングや中国語関連のタスクで優れた結果となっています。


Qwen2
Qwen Team
Project | Paper | GitHub | Demo | Blog
ラベルなし静止画の学習だけ、ビデオ内の動く物体を検出・追跡できるモデル「MASA」
物体追跡は、ロボティクスや自動運転など多くの分野で重要な課題です。特に、複雑なシーンで同一物体を正確に対応付けることが求められます。しかし、従来手法の多くは特定ドメインのラベル付き動画データに依存しており、学習した類似性の埋め込み表現の汎用性が制限されていました。
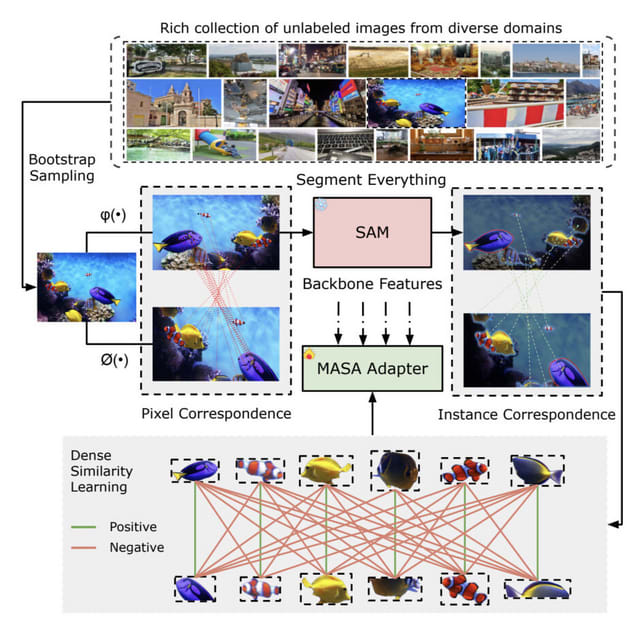
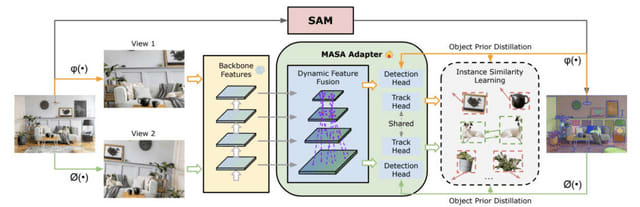
そこで研究チームは、ラベルなしの静止画のみを用いて多様なドメイン間で物体を追跡できる新手法「MASA」(Matching Anything by Segmenting Anything)を提案しました。MASAは、Segment Anything Model(SAM)による豊富な物体セグメンテーション情報を活用し、網羅的なデータ変換によってインスタンスレベルの対応関係を学習できるのが特徴です。
具体的には、SAMの出力を物体領域候補と見なし、大規模な画像コレクションから領域間のマッチングを学習します。さらに、セグメンテーションや検出の基盤モデルと連携できるアダプターを設計しました。これにより、複雑なドメインでもゼロショットで強力な追跡が可能になります。
TAO MOTやBDD100Kなど複数のベンチマークでの評価により、提案手法がラベル付き動画で学習した最新手法と同等以上の性能を、ラベルなし静止画のみで実現できることが示されました。
Matching Anything by Segmenting Anything
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
Project | Paper | GitHub | Demo | Blog
相手が話している適切なタイミングで同時翻訳するAIモデル「StreamSpeech」
同時音声翻訳(Simul-S2ST)は、ストリーミング音声入力を受信しながらターゲット音声を生成する技術です。これは、国際会議やライブ放送、オンライン字幕など、リアルタイムのコミュニケーションにおいて非常に重要です。しかし、翻訳と同時に適切なタイミングで音声を生成することは大きな課題です。これまでの同時音声翻訳は、相手が一区切り話し終わるのを待ってから翻訳していたので、会話がスムーズではありませんでした。
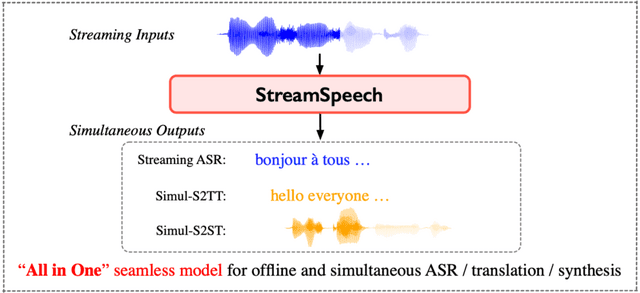
この課題に対し、「StreamSpeech」と呼ばれる新しい同時音声翻訳モデルが提案されました。StreamSpeechは、マルチタスク学習の枠組みの中で、目標言語となる翻訳とそれをいつ翻訳するかのタイミングを同時に学習するモデルです。
StreamSpeechは、リアルタイムの音声翻訳を実現するために、3つの主要なモジュールを組み合わせています。まず、ストリーミング音声エンコーダが入力音声を連続的に処理し、音声の特徴を抽出します。次に、同時テキストデコーダがその特徴を基にテキストを生成し、リアルタイムで翻訳結果を出力します。最後に、同期テキスト・ユニット生成モジュールが翻訳されたテキストを音声合成用のユニットに変換し、音声出力を可能にします。
さらに、StreamSpeechには複数のCTCデコーダが導入されており、音声認識やテキスト翻訳などの補助タスクを通じて、入力音声とテキスト、テキストと出力音声の対応付けを学習します。この情報は、いつ翻訳を開始し、いつ出力するかを決定する際に重要な役割を果たします。
これにより、StreamSpeechは相手の話す速度や内容に合わせて、翻訳のタイミングを自動で調整してくれるため、会話が途切れることなくスムーズに進められます。CVSS-Cベンチマークでの実験では、StreamSpeechがオフラインと同時の両方の音声翻訳タスクで最先端の性能を達成したことが示されました。
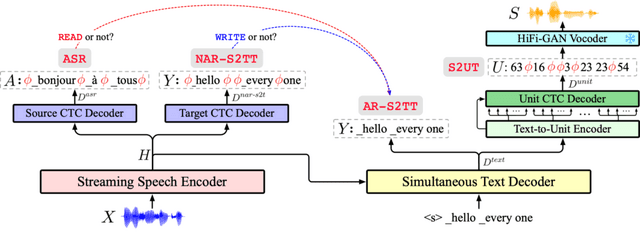
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng
Project | Paper | GitHub | Demo | Blog
OpenAIが大規模言語モデルの中身を理解するモデルを発表。GPT-4の中身は1600万の特徴を持つ
大規模言語モデル(LLM)は、膨大なテキストデータから言語の規則性を学習し、人間のような自然言語処理を可能にします。しかし、その内部表現は高次元で複雑なため、解釈が難しいブラックボックスとなっています。言語モデルの振る舞いを理解し、制御するためには、その内部表現を解釈可能な特徴に分解する必要があります。
この研究では、スパース・オートエンコーダーを用いて、言語モデルの内部表現から解釈可能な特徴を抽出する新手法を提案しています。オートエンコーダーは、データを低次元の潜在表現に圧縮し、そこから元のデータを再構成するニューラルネットワークです。スパース制約を課すことで、潜在表現が疎になり、データの本質的な特徴が少数の次元に集約されます。
言語モデルは多様な概念を学習するため、関連する特徴をすべて捉えるには、オートエンコーダーを大規模化する必要があります。提案手法は、k-スパース・オートエンコーダーを使用してスパース性を直接制御し、トレーニング中に活性化しない潜在変数を減らす改良を加えることで、オートエンコーダーのスケーリング問題を解決します。
本手法のスケーラビリティを実証するため、GPT-4の内部表現を分解した結果、1600万の解釈可能なパターンに分解することに成功しました。

Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, Jeffrey Wu
Project | Paper | GitHub | Demo | Blog
YouTube広告を16倍速であっという間に終わらせるChrome拡張が公開、広告ブロック警告を回避
動画AIが豊作。アニメ絵2枚の間の“中割り”を生成し映像化するAI「ToonCrafter」、画像内キャラを滑らかに踊らせるAI「MusePose」など重要論文5本を解説(生成AIウィークリー)
