
ビジネスシーンや経済指標などでよく用いられるアンケート調査ですが、表される数値はどこまで信用できるものなのでしょうか?
そこで、サイエンスライター・本丸諒 氏の著書『グラフとクイズで見えなかった世界が見えてくる すごい統計学』(飛鳥新社)より、一部を抜粋・編集して統計学でサンプルから推測する方法について解説します。
統計学は「記述」と「推測」の2種類!
統計学の本を読みはじめると、本のはじめのほうに「記述統計学、推測統計学の2つがある」と書いてあります。そして記述統計学とはグラフや表に記述する統計学のこと、推測統計学とはサンプルから母集団を推測する統計学のこと―という説明も添えられているのですが、私にはいまひとつ腑に落ちない分け方に思えます。
というのも、2つに分けるなら、東日本と西日本、北半球と南半球、男と女のように、何かひとつの条件で線引きするものですが、いま述べた形ですと、「グラフ化する」と「推測する」という異なる視点で線引きしているように見えるからです。
そこで私はこの2つの統計学の違い(線引きのポイント)を、
・記述統計学……全数調査をしたデータを扱う統計学のこと
・推測統計学……全数調査をせず、サンプル調査のデータを扱う統計学のこと
このように、 記述統計学と推測統計学とは、「全数調査か、否か」で分けて考える ようにしています。そのほうがスッキリするでしょう。現に、『統計学用語』(アーク出版)という用語辞典で「記述統計学」を引くと、「調査対象とする母集団を構成する個体を『全数調査』して、調査の目的に応じて、その母集団の統計的な性質や特徴を〝記述〞することを目的とした統計学」とあります。わざわざ「全数調査」の部分をカギカッコで囲んで「大事だよ」と注意喚起し、〝記述〞のほうは、あえて〝 〞カッコ書きであることからも、「全数調査が前提だ」と読み取れます。
アンケートから社員の生声が聞こえてくる「記述統計学」
「全数調査」とはいっても、国家全体とか世界全体のデータである必要はありません。
たとえば、Ⅹ社の総務部長が「社員の通勤時間を知って、通勤手当や勤務形態の改善を図りたい」と考えた場合、その全数とはⅩ社の社員全員(60名)を指します。
アンケートの結果を並べたものが(1)の数字です。これを見ただけで、何かわかるでしょうか。そう、データが多数あれば理解度が上がるというものではないのです。
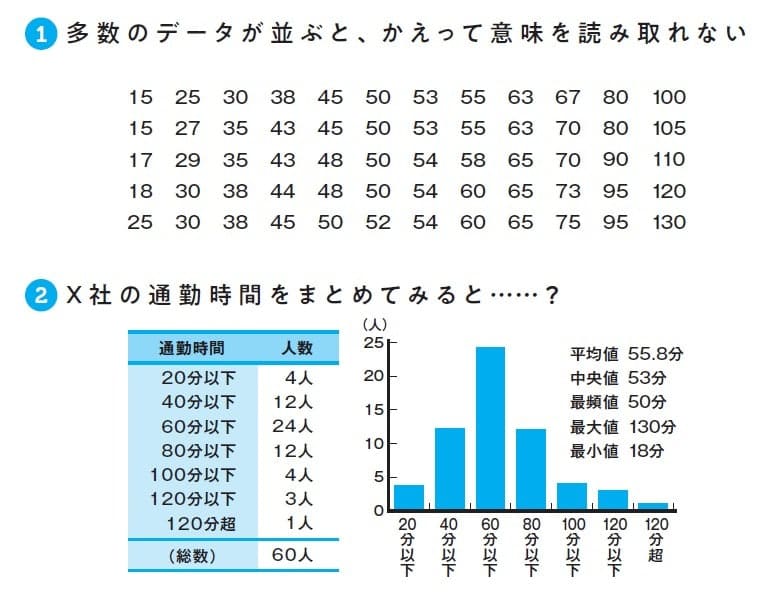
そこで全体を把握しやすくするために、表とグラフにしてさらに60人分の元データを代表する数値(代表値)を抽出してみました(2)。統計学でいう代表値とは、「平均値、中央値、最頻値」の3つでしたね。データの範囲(幅)がどれくらいに分布しているかは「最大値・最小値」で見ることもできますので、それも算出してみました。
代表値やデータの範囲をつかんだおかげで、Ⅹ社の部長は通勤状態を把握することができました。これによって、「在宅ワークを週1で入れれば、社員の疲労度を抑えつつ、手当も減らす」という提案ができるかもしれません。 データは集めること自体が目的ではありません。「分析して、なんらかの対策や提案を目指すこと」が目的 ですからね。
グラフや表にまとめ、代表値(平均値など)やデータの範囲(最大値、最小値)を記述し、分析することで対策を打てるようにする―「記述統計学」と呼ばれるゆえんです。
「推測統計学」で、少ないサンプルでも全体が見える!
もう1つの「推測統計学」の前提は、「全数調査をしない」ことでした。常識的に考えれば全数調査(悉皆調査ともいう)をするほうがよさそうですが、なぜしないのでしょうか?
その理由は、クラスや会社の全数調査ならすぐにできても、国単位や県単位の場合、全数調査をすると、あまりに時間と手間がかかること、さらに費用が莫大になることです。
全数調査の代表は「国勢調査」です。これは5年に1回、実施されますが、2015年の調査費用には650億円かかったとされています。主に地域の自治会や町内会が実際の調査員を出し、調査員に選ばれた人は50~100戸を担当し、国勢調査の説明とその後の回収を担当します。何度伺っても不在の家もありますので、調査員が国勢調査に割く時間はかなりのものとなります(調査員は全国で70万人といわれる)。
そこで、多くの調査では全数調査を行わず、代わりに「サンプル調査」(標本調査ともいう)を採用しています。サンプルですから、そこで得た平均値が、国民全体の平均値とピタリ一致している、という保証はどこにもありません。というより、「近い数値にはなっても、ピタリ一致はしない。誤差が必ず出てくるだろう」と考えるのがふつうでしょう。
では、真の値はどうすればわかるのでしょうか? それは、 おおもと(母集団)の平均値や標準偏差などを「推測する」 のです。このとき、2つの推測方法があります。
点推定……サンプルの平均=母数の平均と考え、ピンポイントで推定する。
区間推定……サンプルの平均値から、少し幅をもって推定する
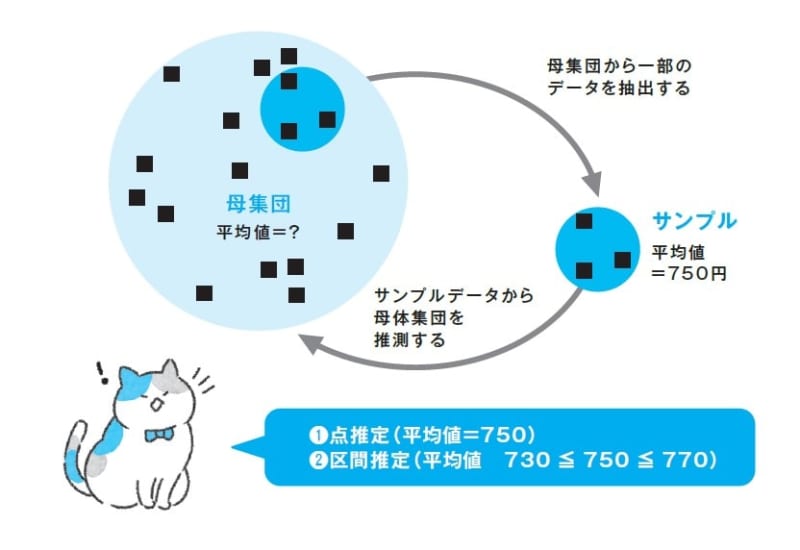
(1)の点推定は、かなりのギャンブルです。1000人のサンプル調査で、ビジネスパーソンの昼食代の平均が「750円」と出れば、全ビジネスパーソンの昼食代を「750円」とピンポイントで推定します。1つの数値で表すため「わかりやすさ」はありますが、「ピタリ同じ」と考えるのは無理があります。また、政権の支持率やテレビの視聴率では誤解も生じますね。
(2)の区間推定は、何度も取ったサンプルの平均値「750円」に幅をもたせます。具体的には一定の数式に「750円」という数値を入れることで、「本当の金額は、95%の信頼度(確率)で730~770円の範囲に入っている」のような幅をもった予測をするのです。この(2)の方法で、サンプル調査で得たデータから母集団の平均値、標準偏差などを推測していきます。これが「推測統計学」です。
そもそも全数調査をしにくい状況では、事実上サンプル調査しか方法がありません。そしてここで大事なことは、「幅をもって推測していること」です。
サンプル調査は、安い、早い、信頼度が高い(高い確率)―という、メリットの多い調査方法で、これを支えているのが統計学(推測統計学)なのです。
しかし、使い方を誤ると誤解やミスリードも起きるので、注意が必要なんです。それらの事例も、この章で解説していきましょう。
サンプルを正しくとるコツは?
家庭の味といえば「みそ汁」と答える日本人は多そうです。実は、このみそ汁にこそ、「サンプル調査の極意」が隠されています。
みそ汁をつくるとき、食卓に出す前に「味見」をしますよね。味が薄い、塩味が足りないと気づけば、そこで微調整します。これがサンプル調査の極意なのです。
料理をするときって、味に偏りがないように、みそ汁全体をよく混ぜたり、みその塊が残っていれば溶かして、全体が同じような濃さになった段階で「味見」をするはずです。
味見はわずかな量で判断しますから(全部を飲んだら意味がない)、お鍋のみそ汁の味が不均等な場合は、味見になりません。味見はサンプルとりですから、 「全体を縮小したサンプル」になっているかどうか、それが味見のポイントです。
全体= サンプルがそっくりなのが理想
サンプル調査も、味見と同じです。 サンプル調査は全数調査の代わりにするものですから、全体(母集団)とサンプルとをできるだけ同じ状態にすることがポイント。 そうでないと、サンプル調査をしても歪んだデータを集めてしまうことになります。
たとえば、「現在、どの新聞を定期購読しているか」を知りたいとします。1万人に聞くとしたら、当然、47都道府県のすべてに、人口比で人数を割り振るでしょう。さらに、各県の市区町村にも人口比で割り振ろうと考えるのが自然です。そのあとは、名前順に1000軒ごとに1軒選ぶ、といったアトランダムな方法で選びます。決して、恣意的に選んではいけません。 恣意的に選べば、偏りが起きるからです。
もし、このアンケートを北海道だけに絞って回答を集めたらどうなるでしょうか。全国紙はともかく、ブロック紙(いくつかのエリアにまたがる地域で販売されている新聞紙)の場合、中日新聞や西日本新聞は実数よりもぐっと少なく示され、同じブロック紙でも北海道新聞は実数よりも大きなシェアになるだろう、と容易に想像できます(北海道新聞、中日新聞、西日本新聞が3大ブロック紙)。このことは、愛知県に絞る、九州に絞る場合も同様です。
歴史的なミスを犯したサンプリング調査
2016年の米大統領選挙はヒラリー・クリントンとトランプの一騎討ちで、多くの世論調査では「クリントン有利」としていたのに、予想は外れました。このときの選挙以上に有名なのが1936年のアメリカの大統領選挙でしょう。
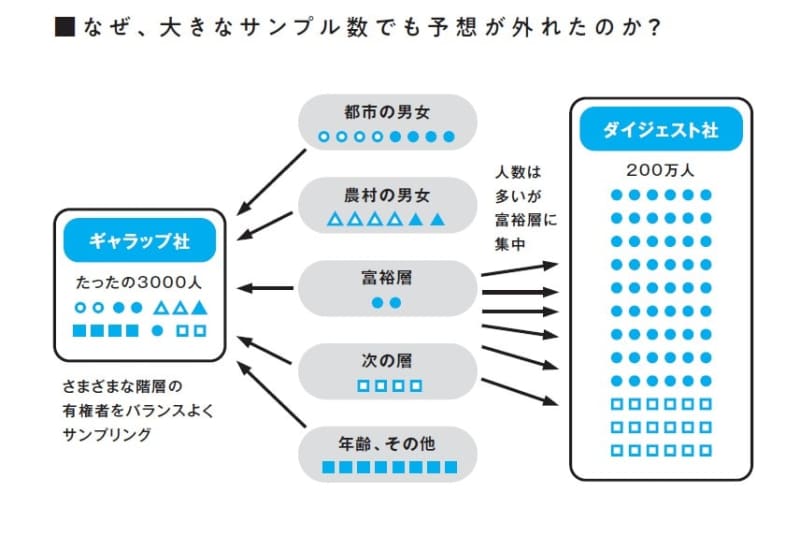
この年は、民主党はルーズベルト候補(現職大統領)、共和党はランドン候補の対決でしたが、無名のギャラップ社(当時の名称はアメリカ世論研究所)は、全米の有権者から3000人の調査で「ルーズベルトが54%で有利」と予想。
これに対し、世論調査で定評のあったリテラリー・ダイジェスト社(以下、ダイジェスト社)は「ランドン57%で勝利」を予想。そのサンプル数は実に200万人で、ギャラップ社の700倍。
その結果はどうだったか……?
46州でルーズベルトが勝ち、選挙人獲得数はルーズベルト523人に対し、ランドンはわずか8人だったのです。ここで問題です!
データdeクイズ
なぜ、200万人ものサンプルを集めたダイジェスト社が予想を外し、たった3000人のサンプルでギャラップ社は的中できたのでしょうか?
答えは、 「ダイジェスト社は、サンプリングのミスをした」です。
予想を大きく外したダイジェスト社の場合、自社の雑誌購読者(高額な雑誌)、電話やクルマの保有者の総計1000万人を選び、そのなかから200万人の回答を得ていました。
当時、電話やクルマを所有できる人は高所得層に限られており、多くは共和党支持者でした。つまり、200万人のサンプルを集めたといっても、ほとんど同じ階層、同じ政党支持者の人々からの回答を得ていたのです。
対するギャラップ社は、都市の男女、農村の男女という地域別・性別、あるいは富裕層、それに次ぐ層などの所得別など、人口比にできるだけ等しく抽出していました。
つまり、「投票者の縮図」を作成し、それに合わせて回答を得ていたのです。結果的に、 正しい縮図をつくれば、小さなサンプルでも全体を反映できる ことがわかったのです。
グラフとクイズで見えなかった世界が見えてくる すごい統計学
著者:本丸諒
[(https://www.amazon.co.jp/gp/product/4864108838)※画像をクリックすると、Amazonの商品ページにリンクします
感動的にわかりやすい!統計の超入門書爆誕!「運」に頼らず、正しい判断ができる。バイアスに惑わされない。フェイクニュースにだまされない。データを制する者は、時代を制する。

